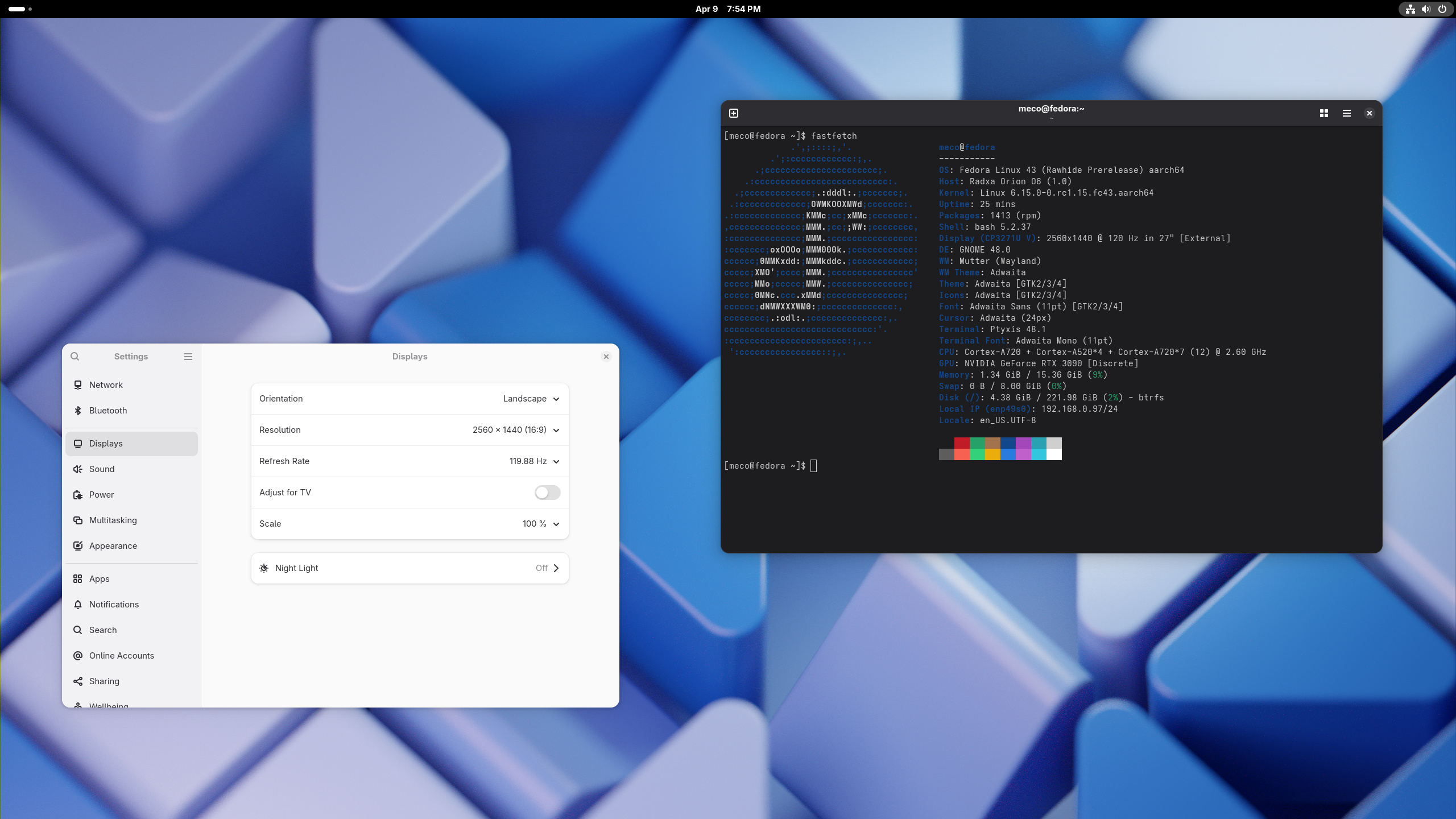
This will be fixed in next release.
Feel free to create issues under edk2-cix repo.
This will be fixed in next release.
Feel free to create issues under edk2-cix repo.
Is uart4 “Power management, voltage, and frequency monitoring” planned on being used? I’ve never seen any output there. Is this actually active but is interactive?
Also, what is the use for the BOOT_STRAP pin (next to the cluster of uart pins)?
Regarding BOOT_STRAP:
https://browser.geekbench.com/v6/compute/3962520
10249 - Vulkan Score
(compared to ~3500 on RK3588)
Is the Debian 12 DT image suppoused to be unstable?
Right now, flashing to image to a NVME and booting from it it works for a while until it crashes and eventually stops working.
Sometime it freeses with visual artifacts as when you have a memory problem on a unstable computer.
After reinstalling the image i try to run memtester, screen glitched out and lost signal half way trought it. Rebooted and it freezed on the desktop.
God damn it $300 for the board, $90 for shipping and an additional suprise $110 Fedex charged me at my door.
I tried with a psu, then with a 90W USB-C and two different m.2 at this point.
Just opened chromium on a fresh image 

There is a stock distro that will give video out in ACPI mode so i could test with something else?
That doesn’t smell good 
Regarding memtester, you can try to pin it to one CPU core to see if that changes anything.
The big cores are 0,9,10,11; the medium cores are 5,6,7,8. The little cores are 1,2,3,4.
You can run for example: taskset -c 1 ./memtester to run it on a little core and see if it
crashes or works. Normally memory tests are agnostic to the CPU’s performance so a little
core should suffice and will draw less juice. If it passes, it would indicate that the RAM is not
at fault. Then you can retry on other cores, then multiple in parallel. If it only fails when using
multiple cores, it could be a power or cooling issue (e.g. heatsink improperly installed). But I
tend to think more about a power issue based on your description (maybe the USB cable itself if you’re using the same with various PSUs).
Ok doing memtester runs only by ssh without anything else attached.
without taskset it freezes and stop responding like after like 2 minutes in.
Did a run on core 1 for 16386mb and it completed OK (this takes a lot of time)
Then tryied to 28700mb and it got “killed” when it tried to mlock, its running now for 28000mb.
Btw, i already checked the cooler and its fine.
EDIT: Ok 28000mb memtest completed on core 1 OK… well ill test one of the middle cores, then core 0.
Also the two m.2 screws came loose inside were the motherboard was, not sure if thats enoght to do damage during shipping.
OK so at least now you know that the RAM is fine. I don’t see why a screw would cause any damage. It’s possible that you’re just facing power issues. Mine only starts at 20V, maybe yours works with a lower voltage supply and sucks more amps from the cable. I’m now powering my board from Radxa’s provided PSU which includes its own cable. For now it’s working fine. It also used to work fine with a GaN 65W PSU and good quality cables previously.
My first attempt was with a ATX PSU that i know it works fine, mainly because i wanted to see if i could get a RTX 3060 working somehow.
Well, right now its not crashing or freezing at all via SSH like it did yesterday, i realised memtest was not crashing anymore and right now it has been running stress-ng --cpu 12 for 30 minutes just fine.
But there is no screen or keyboard attached. I think ill left it like this for a while then use the stress-ng to test the storage and if that fine ill try a screen again.
Edit: ok the image is broken again and i cant boot into the desktop anymore, just stuck on a broken login.
Any of this dmesg seem off?
i wanted to see if i could get a RTX 3060 working somehow.
Did you end up getting it to work? I haven’t been able to get either of my RTX 40 series cards to be detected, I posted more about it in this thread: Problems with PCIe Gen4 on the x8 slot!
re: debian image, for me it seems to be just completely broken/unreliable in many ways. For example, just a simple apt install nvme-cli smartmontools would completely freeze the system and the heartbeat led would quit blinking. I’ve given up and moved on to using mainline 6.14 NixOS with ACPI and things have been a lot more stable.
I’m not spotting anything obviously wrong there. But it could possibly be related to the display if, as you say, it’s working fine when nothing is connected.
ok so im not the only one who had frezees with the debian DT image then. Good to know. You also have the 32GB version? Most people have the 16GB version because i belive those were shipped first.
As for the RTX 3060 i was thinking to bridge the presense pin on the pcie slot and try with that, if that dosent work ill try with a mining riser that should drop the link to x1 2.0 or 3.0.
We have a list of OS that work in ACPI mode?
i had freezes on the ssh too the first day. But yesterday without changing anything it started working properly, then re-flashed the image (thats the other thing, these freezes ends up breaking the desktop env, not longer being able to log in, it just returns to the login screen again, that means there is some serious file corruption happening). And it did work fine on my small screen, i did ran some browser benchmarks and ran glxgears and a youtube video for hours without problems. At least on my small screen, i havent tried to connect my 4K monitor again.
So i dont known what to think really. My worry is that there is actually some issue with it and the heat from using it fixed it, that is not going to be permanent. Ill try to use it again later and see what happens.
The other possibility is that the iGPU is broken, ill need to test it somehow, the OpenGL game i hoped to use to benchmark it crashes via zink on it, but i know this is likely caused by zink.
EDIT: Well when i booted today into the image the login is again broken for no reason
Ill try with ACPI and a normal install.
I wonder if there is any reason for the mesa version of the debian image to be 23.0.x what is really old, ill try to compile the current version.
argh unmeet deps.
builddeps:mesa : Depends: directx-headers-dev (>= 1.613.0) but 1.606.4-1 is to be installed
Depends: meson (>= 1.4.0) but 1.0.1-5 is to be installed
Depends: libdrm-dev (>= 2.4.121) but 2.4.114-1+b1 is to be installed
Depends: wayland-protocols (>= 1.34) but 1.31-1 is to be installed
E: Unable to correct problems, you have held broken packages.
Update:
Managed to build Mesa 24.0.9 but did nothing to me really, there seems to be some missing features on the vulkan driver to properly suport all zink features.
Sidenote the PCIe connection is downgraded though
(Edit: This might be a power saving measure so I need to do further testing)
LnkCap: Port #0, Speed 16GT/s, Width x16, ASPM L0s L1, Exit Latency L0s <512ns, L1 <16us ClockPM+ Surprise- LLActRep- BwNot- ASPMOptComp+ LnkCtl: ASPM Disabled; RCB 64 bytes, LnkDisable- CommClk- ExtSynch- ClockPM+ AutWidDis- BWInt- AutBWInt- LnkSta: Speed 2.5GT/s (downgraded), Width x8 (downgraded)
Have you succes with m.2 and Radxa or Intel wifi adapters? On Rawhide all are hard blocked, even with the latest kernel. Any hint? Regards uli
Great! Could you share those patches, I’d like to try them. Thanks
14 days later in Mid April I’m wondering where this new image can be found? Watching Index of /orion/o6/images/debian daily there’s nothing new. Am I missing something?
Yeah I was wondering that too.