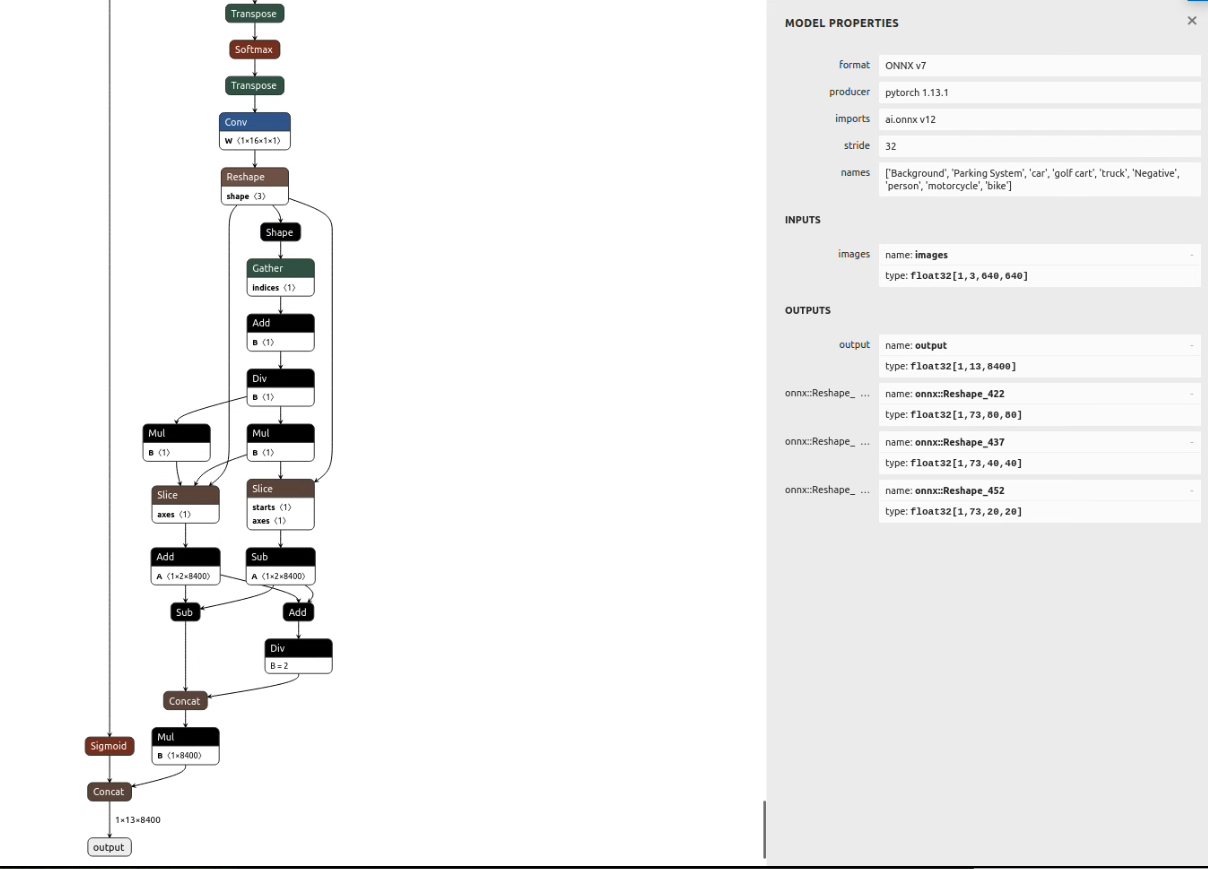
I think I got the wrong tflite last time but also compiled the tflite_runtime native for the rk3588
(venv) (base) stuart@stuart-desktop:~/ultralytics$ yolo predict model=./yolov8n_saved_model/yolov8n_full_integer_quant.tflite imgsz=320 conf=0.25
WARNING ⚠️ Unable to automatically guess model task, assuming 'task=detect'. Explicitly define task for your model, i.e. 'task=detect', 'segment', 'classify', or 'pose'.
WARNING ⚠️ 'source' is missing. Using default 'source=/home/stuart/ultralytics/ultralytics/assets'.
Ultralytics YOLOv8.0.216 🚀 Python-3.11.5 torch-2.1.1 CPU (Cortex-A55)
Loading yolov8n_saved_model/yolov8n_full_integer_quant.tflite for TensorFlow Lite inference...
INFO: Created TensorFlow Lite XNNPACK delegate for CPU.
image 1/2 /home/stuart/ultralytics/ultralytics/assets/bus.jpg: 320x320 7 persons, 1 bus, 39.0ms
image 2/2 /home/stuart/ultralytics/ultralytics/assets/zidane.jpg: 320x320 4 persons, 33.2ms
Speed: 4.6ms preprocess, 36.1ms inference, 3.6ms postprocess per image at shape (1, 3, 320, 320)
Results saved to /home/stuart/ultralytics/runs/detect/predict10
💡 Learn more at https://docs.ultralytics.com/modes/predict
That seems to be running on a single core as the Yolov8 framework is just so great but if hacking in 4 threads to tflite
(venv) (base) stuart@stuart-desktop:~/ultralytics$ yolo predict model=./yolov8n_saved_model/yolov8n_full_integer_quant.tflite imgsz=320 conf=0.25
WARNING ⚠️ Unable to automatically guess model task, assuming 'task=detect'. Explicitly define task for your model, i.e. 'task=detect', 'segment', 'classify', or 'pose'.
WARNING ⚠️ 'source' is missing. Using default 'source=/home/stuart/ultralytics/ultralytics/assets'.
Ultralytics YOLOv8.0.216 🚀 Python-3.11.5 torch-2.1.1 CPU (Cortex-A55)
Loading yolov8n_saved_model/yolov8n_full_integer_quant.tflite for TensorFlow Lite inference...
INFO: Created TensorFlow Lite XNNPACK delegate for CPU.
image 1/2 /home/stuart/ultralytics/ultralytics/assets/bus.jpg: 320x320 7 persons, 1 bus, 26.6ms
image 2/2 /home/stuart/ultralytics/ultralytics/assets/zidane.jpg: 320x320 4 persons, 19.2ms
Speed: 3.4ms preprocess, 22.9ms inference, 3.0ms postprocess per image at shape (1, 3, 320, 320)
Results saved to /home/stuart/ultralytics/runs/detect/predict23
💡 Learn more at https://docs.ultralytics.com/modes/predict
I seem to remember that threading with tflite gives diminishing returns and like better keeping to a core but loading x4 models and running input on a round robin on the large cores (x4) and prob push to 100fps maybe higher.
I had a go with rknn and got it to run but almost x2 as slow as I can on the cpu and it complains about stride length… ?
The output also is crock so gave up.
Running as x4 seperate cli processes
(venv) stuart@stuart-desktop:~/ultralytics$ ./test
WARNING ⚠️ Unable to automatically guess model task, assuming 'task=detect'. Explicitly define task for your model, i.e. 'task=detect', 'segment', 'classify', or 'pose'.
WARNING ⚠️ Unable to automatically guess model task, assuming 'task=detect'. Explicitly define task for your model, i.e. 'task=detect', 'segment', 'classify', or 'pose'.
WARNING ⚠️ Unable to automatically guess model task, assuming 'task=detect'. Explicitly define task for your model, i.e. 'task=detect', 'segment', 'classify', or 'pose'.
WARNING ⚠️ Unable to automatically guess model task, assuming 'task=detect'. Explicitly define task for your model, i.e. 'task=detect', 'segment', 'classify', or 'pose'.
Ultralytics YOLOv8.0.217 🚀 Python-3.10.12 torch-2.1.1 CPU (Cortex-A55)
Ultralytics YOLOv8.0.217 🚀 Python-3.10.12 torch-2.1.1 CPU (Cortex-A55)
Ultralytics YOLOv8.0.217 🚀 Python-3.10.12 torch-2.1.1 CPU (Cortex-A55)
Ultralytics YOLOv8.0.217 🚀 Python-3.10.12 torch-2.1.1 CPU (Cortex-A55)
Loading yolov8n_saved_model/yolov8n_full_integer_quant.tflite for TensorFlow Lite inference...
INFO: Created TensorFlow Lite XNNPACK delegate for CPU.
Loading yolov8n_saved_model/yolov8n_full_integer_quant.tflite for TensorFlow Lite inference...
INFO: Created TensorFlow Lite XNNPACK delegate for CPU.
Loading yolov8n_saved_model/yolov8n_full_integer_quant.tflite for TensorFlow Lite inference...
INFO: Created TensorFlow Lite XNNPACK delegate for CPU.
Loading yolov8n_saved_model/yolov8n_full_integer_quant.tflite for TensorFlow Lite inference...
INFO: Created TensorFlow Lite XNNPACK delegate for CPU.
image 1/28 /tmp/images/0x0.webp: 320x320 1 car, 38.5ms
image 1/28 /tmp/images/0x0.webp: 320x320 1 car, 37.9ms
image 1/28 /tmp/images/0x0.webp: 320x320 1 car, 42.3ms
image 2/28 /tmp/images/1_JS286428040.webp: 320x320 3 persons, 30.9ms
image 2/28 /tmp/images/1_JS286428040.webp: 320x320 3 persons, 30.2ms
image 2/28 /tmp/images/1_JS286428040.webp: 320x320 3 persons, 95.0ms
image 1/28 /tmp/images/0x0.webp: 320x320 1 car, 44.6ms
image 3/28 /tmp/images/1d6830cc-9382-11ed-ad8c-0210609a3fe2.jpg: 320x320 5 persons, 36.6ms
image 2/28 /tmp/images/1_JS286428040.webp: 320x320 3 persons, 32.7ms
image 3/28 /tmp/images/1d6830cc-9382-11ed-ad8c-0210609a3fe2.jpg: 320x320 5 persons, 45.8ms
image 3/28 /tmp/images/1d6830cc-9382-11ed-ad8c-0210609a3fe2.jpg: 320x320 5 persons, 33.4ms
image 4/28 /tmp/images/220805-border-collie-play-mn-1100-82d2f1.webp: 320x320 1 dog, 31.2ms
image 5/28 /tmp/images/90-vauxhall-corsa-electric-best-small-cars.jpg: 320x320 1 car, 29.4ms
image 4/28 /tmp/images/220805-border-collie-play-mn-1100-82d2f1.webp: 320x320 1 dog, 52.2ms
image 3/28 /tmp/images/1d6830cc-9382-11ed-ad8c-0210609a3fe2.jpg: 320x320 5 persons, 42.7ms
image 4/28 /tmp/images/220805-border-collie-play-mn-1100-82d2f1.webp: 320x320 1 dog, 30.6ms
image 6/28 /tmp/images/Can-a-single-person-own-a-firm-in-India.jpg: 320x320 1 person, 30.4ms
image 5/28 /tmp/images/90-vauxhall-corsa-electric-best-small-cars.jpg: 320x320 1 car, 32.9ms
image 4/28 /tmp/images/220805-border-collie-play-mn-1100-82d2f1.webp: 320x320 1 dog, 33.0ms
image 5/28 /tmp/images/90-vauxhall-corsa-electric-best-small-cars.jpg: 320x320 1 car, 30.3ms
image 7/28 /tmp/images/DCTM_Penguin_UK_DK_AL697473_RGB_PNG_namnse.webp: 320x320 1 cat, 29.7ms
image 6/28 /tmp/images/Can-a-single-person-own-a-firm-in-India.jpg: 320x320 1 person, 31.5ms
image 5/28 /tmp/images/90-vauxhall-corsa-electric-best-small-cars.jpg: 320x320 1 car, 34.9ms
image 6/28 /tmp/images/Can-a-single-person-own-a-firm-in-India.jpg: 320x320 1 person, 44.4ms
image 8/28 /tmp/images/Planning-a-teen-party-narrow.jpg: 320x320 9 persons, 30.1ms
image 6/28 /tmp/images/Can-a-single-person-own-a-firm-in-India.jpg: 320x320 1 person, 31.8ms
image 7/28 /tmp/images/DCTM_Penguin_UK_DK_AL697473_RGB_PNG_namnse.webp: 320x320 1 cat, 42.6ms
image 7/28 /tmp/images/DCTM_Penguin_UK_DK_AL697473_RGB_PNG_namnse.webp: 320x320 1 cat, 29.7ms
image 9/28 /tmp/images/RollingStoneAwardsAaronParsonsPhotography23.11_highres_30-1024x683.jpg: 320x320 4 persons, 30.6ms
image 7/28 /tmp/images/DCTM_Penguin_UK_DK_AL697473_RGB_PNG_namnse.webp: 320x320 1 cat, 30.3ms
image 8/28 /tmp/images/Planning-a-teen-party-narrow.jpg: 320x320 9 persons, 29.7ms
image 8/28 /tmp/images/Planning-a-teen-party-narrow.jpg: 320x320 9 persons, 38.5ms
image 8/28 /tmp/images/Planning-a-teen-party-narrow.jpg: 320x320 9 persons, 29.5ms
image 10/28 /tmp/images/VIER PFOTEN_2016-07-08_011-5184x2712-1200x628.jpg: 320x320 1 cat, 33.2ms
image 9/28 /tmp/images/RollingStoneAwardsAaronParsonsPhotography23.11_highres_30-1024x683.jpg: 320x320 4 persons, 31.0ms
image 9/28 /tmp/images/RollingStoneAwardsAaronParsonsPhotography23.11_highres_30-1024x683.jpg: 320x320 4 persons, 33.0ms
image 9/28 /tmp/images/RollingStoneAwardsAaronParsonsPhotography23.11_highres_30-1024x683.jpg: 320x320 4 persons, 29.8ms
image 11/28 /tmp/images/XLB_4.png: 320x320 1 dog, 30.1ms
image 10/28 /tmp/images/VIER PFOTEN_2016-07-08_011-5184x2712-1200x628.jpg: 320x320 1 cat, 30.8ms
image 10/28 /tmp/images/VIER PFOTEN_2016-07-08_011-5184x2712-1200x628.jpg: 320x320 1 cat, 31.0ms
image 10/28 /tmp/images/VIER PFOTEN_2016-07-08_011-5184x2712-1200x628.jpg: 320x320 1 cat, 29.5ms
image 12/28 /tmp/images/_119254021_lotusemira.jpg: 320x320 1 car, 30.7ms
image 11/28 /tmp/images/XLB_4.png: 320x320 1 dog, 30.1ms
image 11/28 /tmp/images/XLB_4.png: 320x320 1 dog, 31.1ms
image 13/28 /tmp/images/athletic-women-walking-together-on-remote-trail-royalty-free-image-1626378592.jpg: 320x320 5 persons, 30.1ms
image 11/28 /tmp/images/XLB_4.png: 320x320 1 dog, 32.8ms
image 12/28 /tmp/images/_119254021_lotusemira.jpg: 320x320 1 car, 29.8ms
image 12/28 /tmp/images/_119254021_lotusemira.jpg: 320x320 1 car, 30.5ms
image 14/28 /tmp/images/birthdayparty.jpg: 320x320 5 persons, 30.3ms
image 12/28 /tmp/images/_119254021_lotusemira.jpg: 320x320 1 car, 29.7ms
image 13/28 /tmp/images/athletic-women-walking-together-on-remote-trail-royalty-free-image-1626378592.jpg: 320x320 5 persons, 31.1ms
image 13/28 /tmp/images/athletic-women-walking-together-on-remote-trail-royalty-free-image-1626378592.jpg: 320x320 5 persons, 31.4ms
image 15/28 /tmp/images/bloat_md.jpg: 320x320 3 persons, 3 bicycles, 1 bench, 30.1ms
image 13/28 /tmp/images/athletic-women-walking-together-on-remote-trail-royalty-free-image-1626378592.jpg: 320x320 5 persons, 31.9ms
image 14/28 /tmp/images/birthdayparty.jpg: 320x320 5 persons, 40.1ms
image 14/28 /tmp/images/birthdayparty.jpg: 320x320 5 persons, 32.6ms
image 16/28 /tmp/images/bus.jpg: 320x320 5 persons, 1 bus, 29.5ms
image 14/28 /tmp/images/birthdayparty.jpg: 320x320 5 persons, 39.0ms
image 15/28 /tmp/images/bloat_md.jpg: 320x320 3 persons, 3 bicycles, 1 bench, 30.4ms
image 15/28 /tmp/images/bloat_md.jpg: 320x320 3 persons, 3 bicycles, 1 bench, 31.8ms
image 15/28 /tmp/images/bloat_md.jpg: 320x320 3 persons, 3 bicycles, 1 bench, 30.5ms
image 17/28 /tmp/images/gettyimages-1094874726.png: 320x320 1 dog, 1 sheep, 30.3ms
image 16/28 /tmp/images/bus.jpg: 320x320 5 persons, 1 bus, 29.7ms
image 16/28 /tmp/images/bus.jpg: 320x320 5 persons, 1 bus, 32.5ms
image 16/28 /tmp/images/bus.jpg: 320x320 5 persons, 1 bus, 29.5ms
image 18/28 /tmp/images/image (1).jpg: 320x320 5 persons, 38.7ms
image 17/28 /tmp/images/gettyimages-1094874726.png: 320x320 1 dog, 1 sheep, 30.6ms
image 17/28 /tmp/images/gettyimages-1094874726.png: 320x320 1 dog, 1 sheep, 30.7ms
image 19/28 /tmp/images/image.jpg: 320x320 1 car, 5 trucks, 30.0ms
image 17/28 /tmp/images/gettyimages-1094874726.png: 320x320 1 dog, 1 sheep, 29.7ms
image 18/28 /tmp/images/image (1).jpg: 320x320 5 persons, 35.0ms
image 18/28 /tmp/images/image (1).jpg: 320x320 5 persons, 31.9ms
image 20/28 /tmp/images/images.jpg: 320x320 2 persons, 30.2ms
image 18/28 /tmp/images/image (1).jpg: 320x320 5 persons, 30.2ms
image 19/28 /tmp/images/image.jpg: 320x320 1 car, 5 trucks, 29.7ms
image 21/28 /tmp/images/kiss-haunted-house-party-watch-back-performances.jpg: 320x320 4 persons, 29.6ms
image 19/28 /tmp/images/image.jpg: 320x320 1 car, 5 trucks, 32.4ms
image 19/28 /tmp/images/image.jpg: 320x320 1 car, 5 trucks, 31.7ms
image 20/28 /tmp/images/images.jpg: 320x320 2 persons, 32.7ms
image 22/28 /tmp/images/man-walking-1024x651.jpg: 320x320 2 persons, 29.6ms
image 20/28 /tmp/images/images.jpg: 320x320 2 persons, 30.5ms
image 20/28 /tmp/images/images.jpg: 320x320 2 persons, 30.8ms
image 21/28 /tmp/images/kiss-haunted-house-party-watch-back-performances.jpg: 320x320 4 persons, 31.3ms
image 23/28 /tmp/images/party-games.png: 320x320 6 persons, 29.7ms
image 21/28 /tmp/images/kiss-haunted-house-party-watch-back-performances.jpg: 320x320 4 persons, 29.0ms
image 21/28 /tmp/images/kiss-haunted-house-party-watch-back-performances.jpg: 320x320 4 persons, 31.4ms
image 22/28 /tmp/images/man-walking-1024x651.jpg: 320x320 2 persons, 30.1ms
image 24/28 /tmp/images/truck.webp: 320x320 1 truck, 29.6ms
image 22/28 /tmp/images/man-walking-1024x651.jpg: 320x320 2 persons, 30.9ms
image 22/28 /tmp/images/man-walking-1024x651.jpg: 320x320 2 persons, 30.0ms
image 23/28 /tmp/images/party-games.png: 320x320 6 persons, 30.2ms
image 25/28 /tmp/images/walking.jpg: 320x320 1 person, 29.6ms
image 23/28 /tmp/images/party-games.png: 320x320 6 persons, 29.9ms
image 23/28 /tmp/images/party-games.png: 320x320 6 persons, 30.4ms
image 24/28 /tmp/images/truck.webp: 320x320 1 truck, 30.0ms
image 24/28 /tmp/images/truck.webp: 320x320 1 truck, 36.3ms
image 24/28 /tmp/images/truck.webp: 320x320 1 truck, 39.0ms
image 26/28 /tmp/images/why-do-cats-have-whiskers-1.jpg: 320x320 (no detections), 31.1ms
image 25/28 /tmp/images/walking.jpg: 320x320 1 person, 32.9ms
image 25/28 /tmp/images/walking.jpg: 320x320 1 person, 29.7ms
image 25/28 /tmp/images/walking.jpg: 320x320 1 person, 29.8ms
image 27/28 /tmp/images/why-is-it-called-a-semi-truck.jpg: 320x320 1 truck, 31.9ms
image 26/28 /tmp/images/why-do-cats-have-whiskers-1.jpg: 320x320 (no detections), 31.1ms
image 26/28 /tmp/images/why-do-cats-have-whiskers-1.jpg: 320x320 (no detections), 31.5ms
image 26/28 /tmp/images/why-do-cats-have-whiskers-1.jpg: 320x320 (no detections), 29.8ms
image 28/28 /tmp/images/wild-dog.jpg: 320x320 1 sheep, 30.2ms
Speed: 7.2ms preprocess, 31.1ms inference, 6.3ms postprocess per image at shape (1, 3, 320, 320)
💡 Learn more at https://docs.ultralytics.com/modes/predict
image 27/28 /tmp/images/why-is-it-called-a-semi-truck.jpg: 320x320 1 truck, 30.5ms
image 27/28 /tmp/images/why-is-it-called-a-semi-truck.jpg: 320x320 1 truck, 29.6ms
image 27/28 /tmp/images/why-is-it-called-a-semi-truck.jpg: 320x320 1 truck, 29.8ms
image 28/28 /tmp/images/wild-dog.jpg: 320x320 1 sheep, 30.0ms
Speed: 6.7ms preprocess, 33.4ms inference, 6.7ms postprocess per image at shape (1, 3, 320, 320)
💡 Learn more at https://docs.ultralytics.com/modes/predict
image 28/28 /tmp/images/wild-dog.jpg: 320x320 1 sheep, 46.2ms
Speed: 6.7ms preprocess, 32.8ms inference, 6.4ms postprocess per image at shape (1, 3, 320, 320)
💡 Learn more at https://docs.ultralytics.com/modes/predict
image 28/28 /tmp/images/wild-dog.jpg: 320x320 1 sheep, 30.1ms
Speed: 6.9ms preprocess, 34.6ms inference, 7.4ms postprocess per image at shape (1, 3, 320, 320)
💡 Learn more at https://docs.ultralytics.com/modes/predict