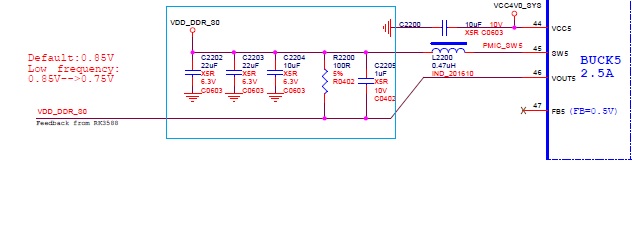
Hello,
I’ve been running Rock 5B as a server for some time (before this it was often collecting dust). I was booting off eMMC but I switched to an NVME rootfs (Joshua Riek’s Ubuntu 24.04, latest 6.1 kernel from this distro).
The reason I switched was because some checksums, for example when building an Armbian image, were failing and I thought it was due to eMMC being corrupted or the command queue error (which I never attempted to mitigate).
However, after a while I started observing similar behaviour on the NVME. Some database files became corrupt for no reason etc.
I ran memtester and noticed many failures. This is the command for example:
sudo memtester 8G 5 - 5 passes, 8 GB. The errors appear instantly, here is an example:
FAILURE: possible bad address line at offset 0x00000000bbdc9200.
...
FAILURE: 0x0000000000000052 != 0x0000000000000008 at offset 0x0000000076b663f0.
FAILURE: 0x00000000000000f7 != 0x0000000000000008 at offset 0x0000000076b66a10.
FAILURE: 0x0000000000000048 != 0x0000000000000008 at offset 0x0000000076b66a20.
FAILURE: 0x00000000000000ba != 0x0000000000000008 at offset 0x0000000076b66a30.
FAILURE: 0x0000000000000091 != 0x0000000000000008 at offset 0x0000000076b66a70.
FAILURE: 0x00000000000000a2 != 0x0000000000000008 at offset 0x0000000076b66a90.
FAILURE: 0x00000000000000f8 != 0x0000000000000008 at offset 0x0000000076b66ab0.
FAILURE: 0x0000000000000048 != 0x0000000000000008 at offset 0x0000000076b66ac0.
FAILURE: 0x00000000000000ef != 0x0000000000000008 at offset 0x0000000076b66ad0.
FAILURE: 0x0000000000000052 != 0x0000000000000008 at offset 0x0000000076b66af0.
...
FAILURE: 0xffffffffffffffe3 != 0xffffffffffffffff at offset 0x0000000076b40ad0.
FAILURE: 0xffffffffffffffef != 0xffffffffffffffff at offset 0x0000000076b40ae0.
FAILURE: 0xffffffffffffff08 != 0xffffffffffffffff at offset 0x0000000076b40af0.
FAILURE: 0xffffffffffffffbf != 0xffffffffffffffff at offset 0x0000000076b40b00.
FAILURE: 0xffffffffffffff4f != 0xffffffffffffffff at offset 0x0000000076b40b10.
FAILURE: 0xffffffffffffff2c != 0xffffffffffffffff at offset 0x0000000076b40b30.
FAILURE: 0xffffffffffffffe0 != 0xffffffffffffffff at offset 0x0000000076b40b50.
FAILURE: 0xffffffffffffff55 != 0xffffffffffffffff at offset 0x0000000076b40b70.
FAILURE: 0xfffffffffffffffe != 0xffffffffffffffff at offset 0x0000000076b40b80.
FAILURE: 0xffffffffffffffc9 != 0xffffffffffffffff at offset 0x0000000076b40b90.
FAILURE: 0xffffffffffffffef != 0xffffffffffffffff at offset 0x0000000076b40ba0.
FAILURE: 0xffffffffffffffa2 != 0xffffffffffffffff at offset 0x0000000076b40bb0.
...
FAILURE: 0x0000000000000005 != 0x0000000000000001 at offset 0x0000000076b65a00.
FAILURE: 0x0000000000000091 != 0x0000000000000001 at offset 0x0000000076b65a10.
FAILURE: 0x00000000000000cd != 0x0000000000000001 at offset 0x0000000076b65a30.
FAILURE: 0x0000000000000062 != 0x0000000000000001 at offset 0x0000000076b65a50.
FAILURE: 0x0000000000000098 != 0x0000000000000001 at offset 0x0000000076b65a70.
FAILURE: 0x0000000000000051 != 0x0000000000000001 at offset 0x0000000076b65a90.
FAILURE: 0x00000000000000cd != 0x0000000000000001 at offset 0x0000000076b65ab0.
FAILURE: 0x000000000000000d != 0x0000000000000001 at offset 0x0000000076b65ad0.
FAILURE: 0x0000000000000041 != 0x0000000000000001 at offset 0x0000000076b65ae0.
FAILURE: 0x0000000000000019 != 0x0000000000000001 at offset 0x0000000076b65af0.
FAILURE: 0x0000000000000068 != 0x0000000000000001 at offset 0x0000000076b65b10.
FAILURE: 0x0000000000000011 != 0x0000000000000001 at offset 0x0000000076b65b20.
FAILURE: 0x0000000000000013 != 0x0000000000000001 at offset 0x0000000076b65b30.
FAILURE: 0x0000000000000051 != 0x0000000000000001 at offset 0x0000000076b65b50.
FAILURE: 0x0000000000000097 != 0x0000000000000001 at offset 0x0000000076b65b70.
FAILURE: 0x00000000000000fe != 0x0000000000000001 at offset 0x0000000076b65b90.
Basically every test ends in an error. The errors seem to appear more quickly after a reboot if I run the board with the default or performance set of governors (GPU, DMC, CPU) than when I use powersave (but eventually they also appear on powersave). I also tried to decrease the RAM speed but it did not help.
Is there a way to diagnose it better or maybe even fix? I don’t have any important data on the board now.