I think I’m having the start of an explanation for the slightly lower perf on CPU0:
$ watch -n 1 -d 'grep hda /proc/interrupts'
Every 1.0s: grep hda /proc/interrupts orion-o6: Sat Feb 1 21:17:58 2025
160: 6811576 0 0 0 0 0 0 0 0 0 0 0 PDCv1 234 Level hda irq
This “hda” interrupt strikes at 50k per second on core 0. I’m now trying to figure what causes this. Unloading all snd_* modules crashed the system so I’ll need to blacklist them instead.
Edit: that was it. Here’s the new c2clat output after blacklisting all snd_* modules:
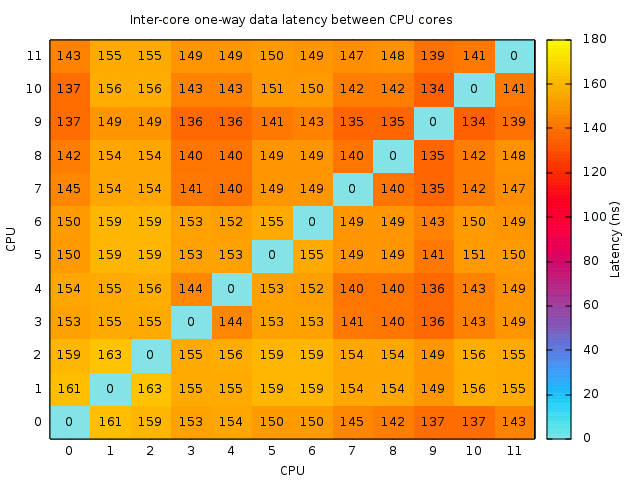
So now I think that core 0 is exactly the same as core 11, and once that driver is removed, there’s no reason not to use it for measurements.