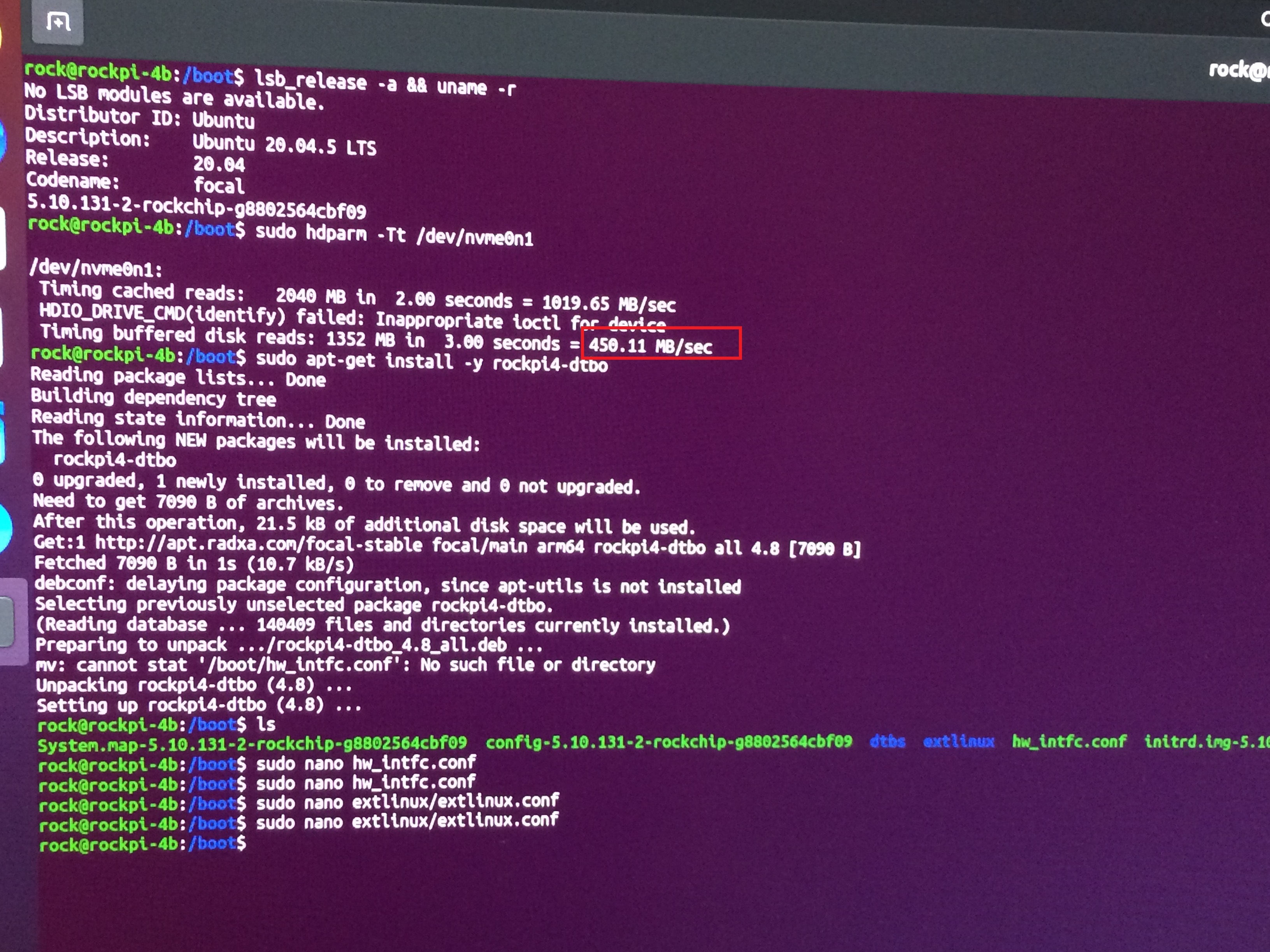
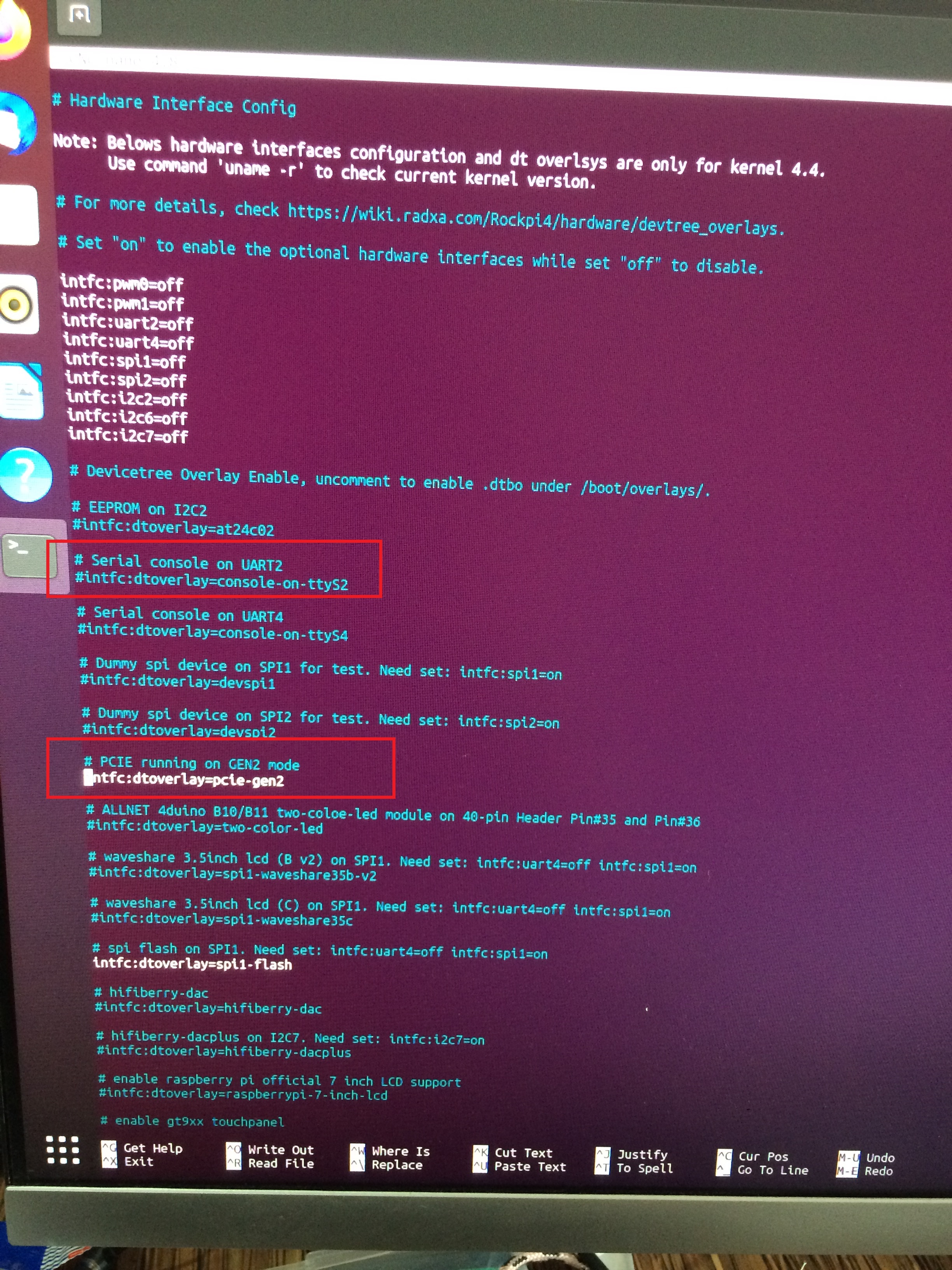
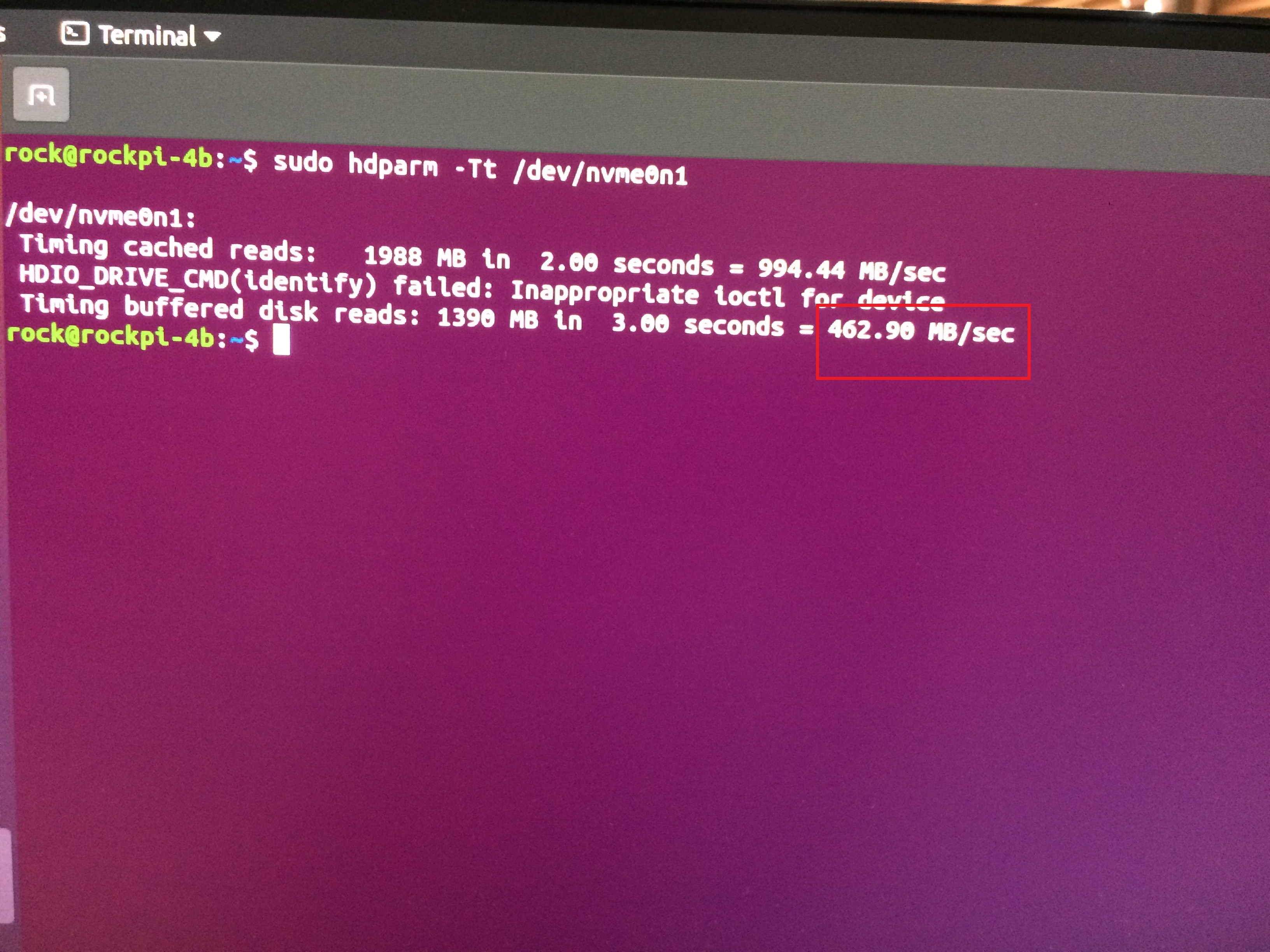
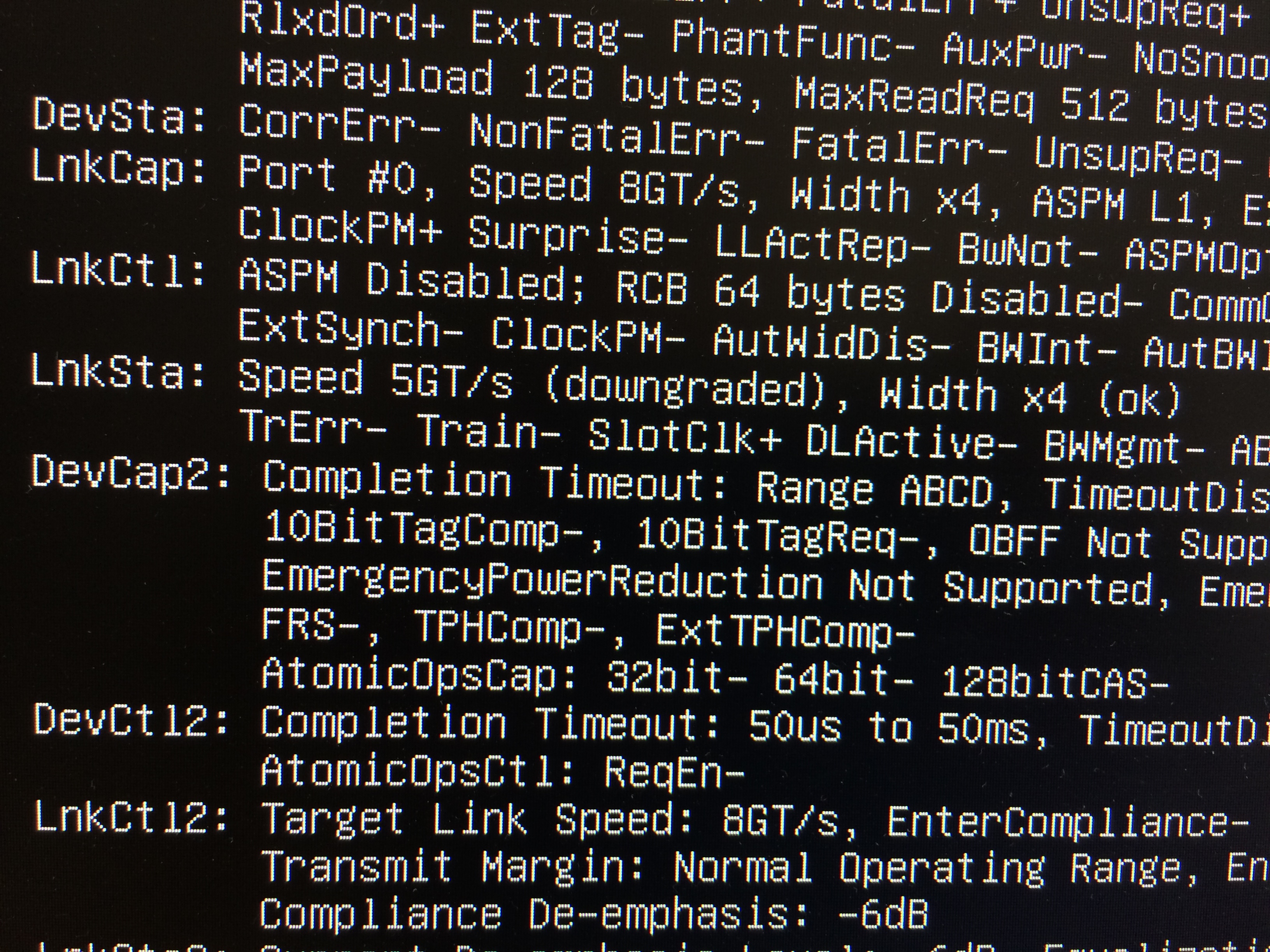
Thank you very much. I have run the sudo lspci -vv command, saved the outputs (when PCIE2 enabled/disabled from hw_init.conf). I used diff command to compare them and nothing changed. As I have understood, they reported speed of 5GT/s. See below:
When I checked in wikipedia about PCIE speeds, it looks like 5GT/s correspond to PCIE2. Does it mean that Rock Pi 4 uses PCIE2 as default? It would be strange given that they have instructions/settings to enable pcie2.
Furthermore, my speeds reported by hdparm are ~450MB/s. In following blog post, it is said: “After following his instructions of turning on PCIe gen 2 mode, I re-ran the benchmark. I got a whopping 1.2GB/s read speeds and a staggering 1.4GB/s write speeds”
That confirms at the PCIe layer being everything perfect since RK3399 is limited to Gen2 x4. As for your low hdparm numbers that’s then an indication that the OS image you’re using ships with crappy settings (something pretty common in the SBC world).
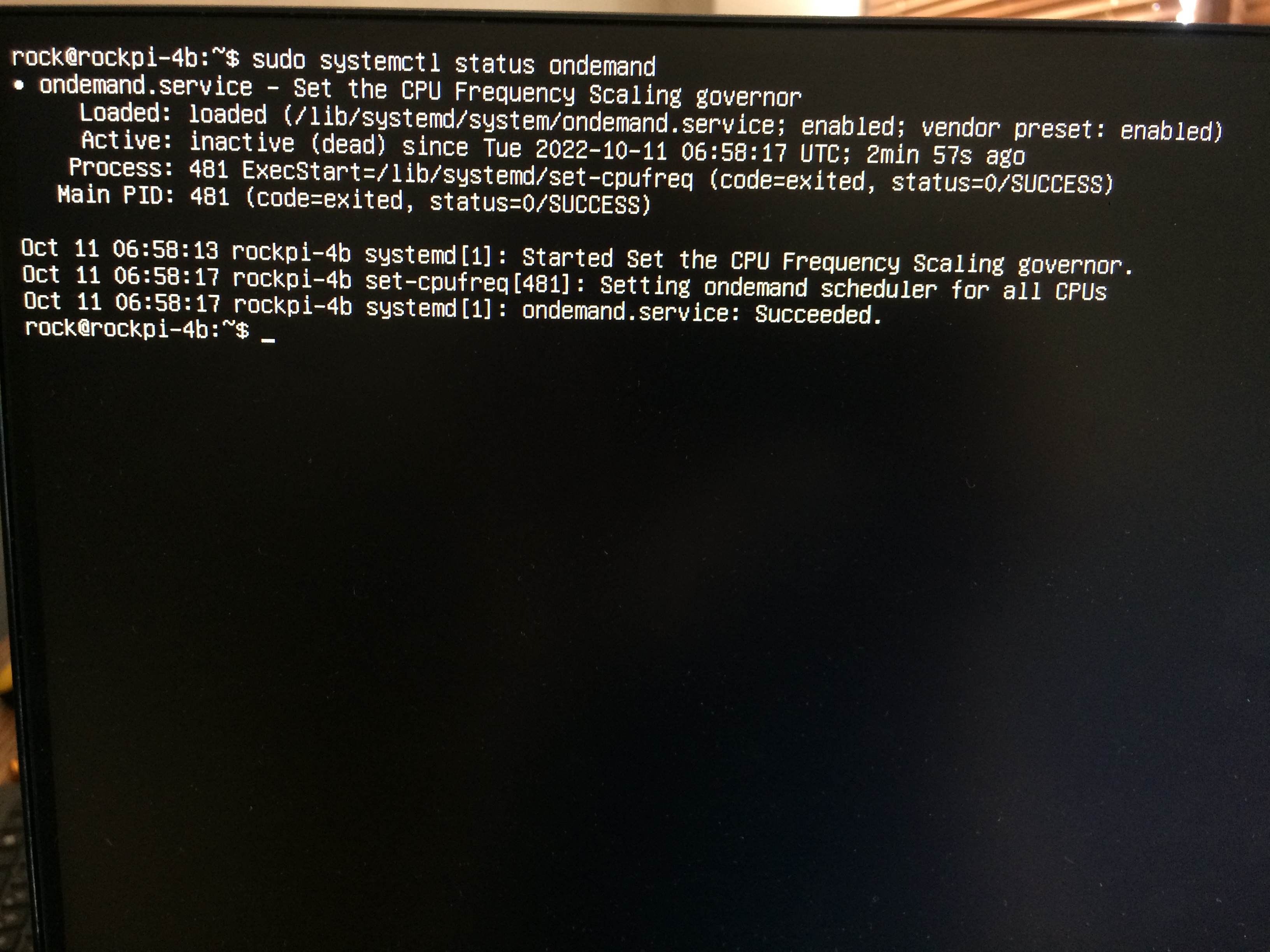
hdparm is the wrong tool anyway (since using a laughably small block size from last century). And most probably there’s something wrong with cpufreq scaling (keeping the ARM cores on their lowest clock which results in poor I/O performance regardless of PCIe link speed). What does this output:
Well, Ubuntu on random ARM SBC is pretty much broken performance-wise, at least it ends up with crappy I/O performance by design
Radxa people know but don’t care… see for example the comments here. And see these observations that are now 6 years old.
As already said the issue is most likely CPU cores remaining at lowest clockspeeds when doing I/O. The recipe to improve this on ARM is known since a long time but gets ignored.
If you follow these simple steps then I bet your numbers will be at least twice as high but at the price of a higher idle consumption. The only real way to deal correctly with this is using ondemand with io_is_busy and friends.
Thank you very much for detailed information. Though unfortunately I don’t have much knowledge in this domain(about “ondemand”).
I followed the steps in the link, but there was no impact at all(tested with hdparm -Tt /dev/nvmen0n1).
Currently, I am using Linux 5, I previously tested it with Linux 4 on the same OS, also tested on Debian, on different SSDs, and the speed doesn’t change.
With RK3399, a good SSD and appropriate benchmark methodology really testing direct i/o with Gen2 speeds you should get numbers exceeding 1400 MiB/sec both reading and writing. RockPro64 example and Theobroma Systems’ RK3399-Q7 SOM example.
Moral of the story: lspci confirmed that you’re now useing a higher PCIe link speed and also have no problems with link width (dusty/dirty contacts can result in just a x2 or even an x1 connection). And asides what all these benchmarks tell I guess in reality you’re after better real-world storage performance? And this is sabotaged by ignorance at Radxa’s side who ship with crappy settings
You can compare what’s happening when setting cpufreq governor to performance and powersave. The former brings the optimal storage performance while the latter is what you’ll get with real-world tasks since Radxa’s ondemand settings result in the CPU cores being most of the times on lowest cpufreq with I/O tasks. So even if a benchmark will tell you ‘everything is fine’ real-world storage performance is not
The contents should be fine. But as already said you need to either reboot or do a systemctl restart cpufrequtils. It’s important that the following reads performance:
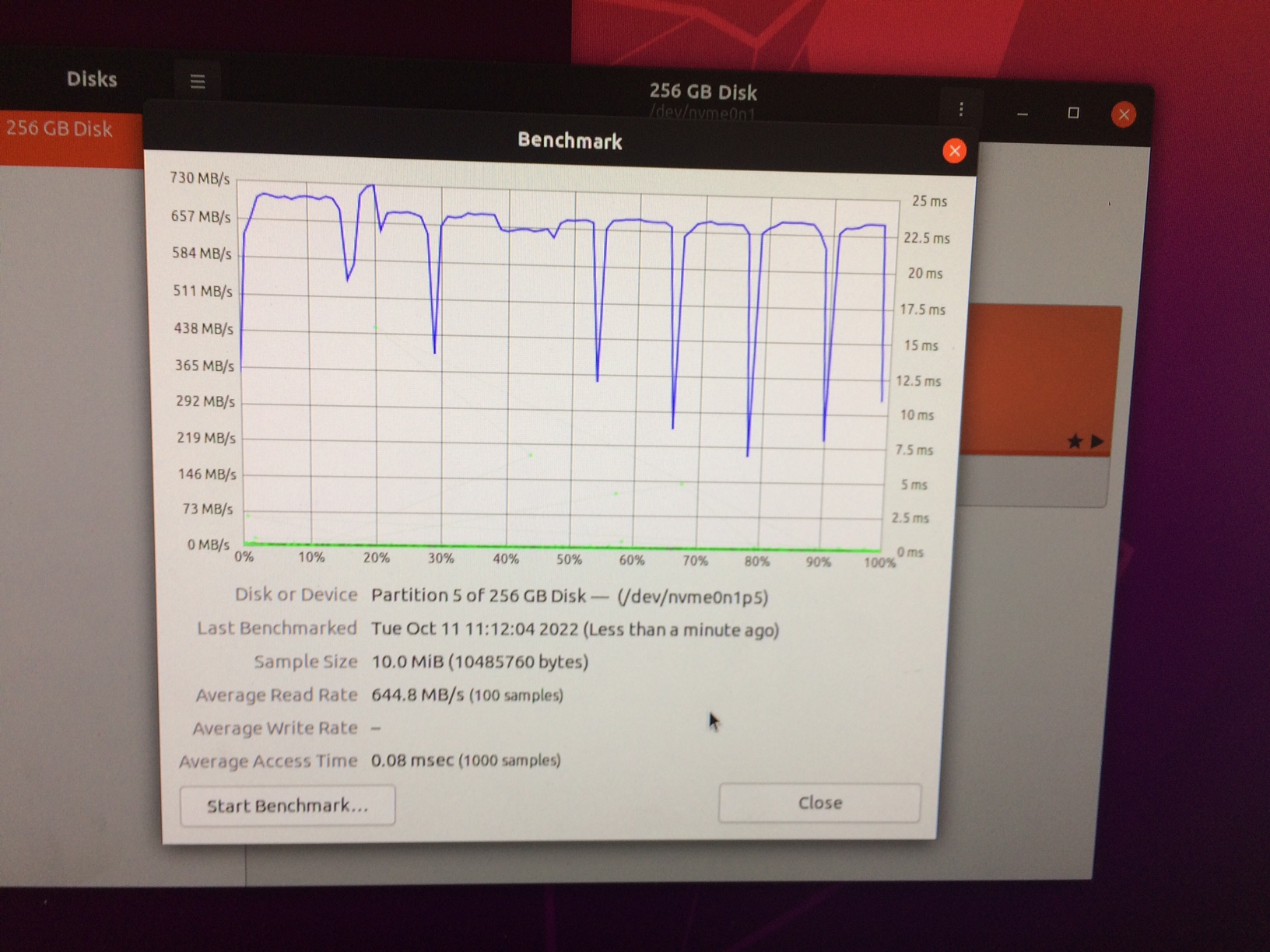
One final thing. I checked default speed where cat /sys/devices/system/cpu/cpu?/cpufreq/scaling_governor is ondemand
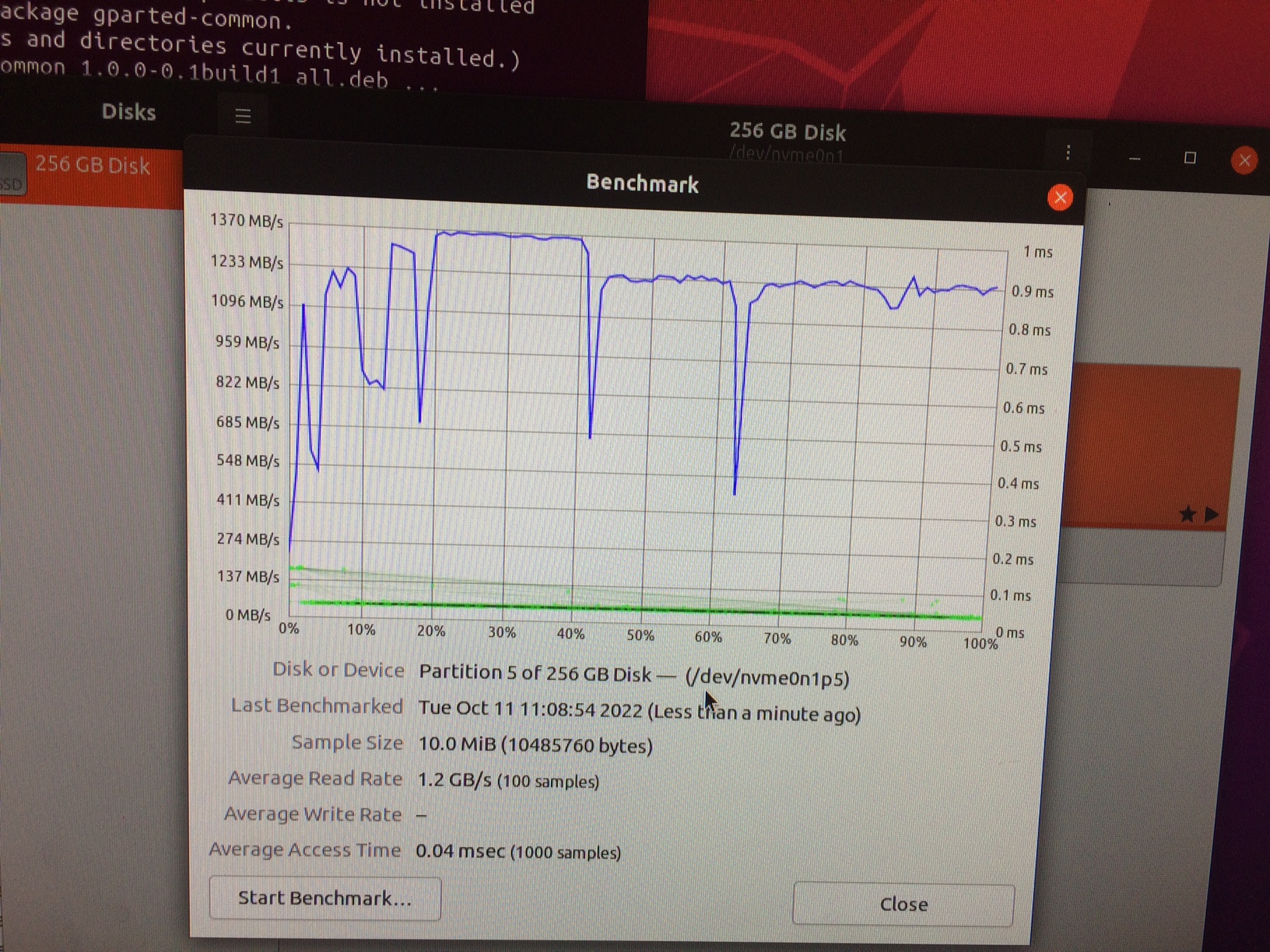
vs when we modify it to be performance.
According to the results, it seems that ondemand performance seems pretty good(doesn’t differ from performance).
Perhaps there is no need to deal with performance at all?