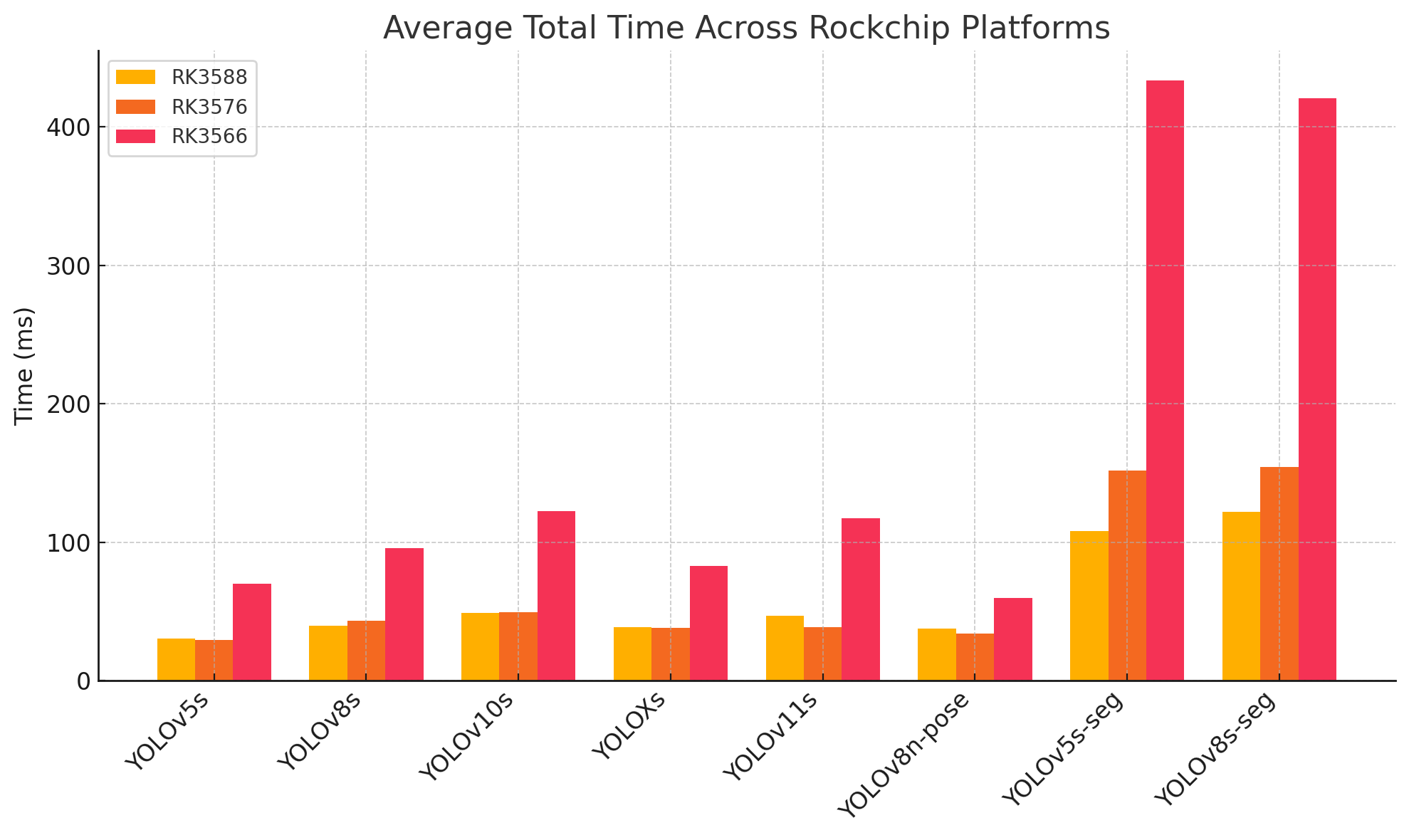
Recently I updated GitHub - swdee/go-rknnlite: CGO bindings to RKNN-Toolkit2 to perform Inferencing in Go on Rockchip NPU to support other models in the RK35xx series, specifically to compare the two core 6 TOPS NPU of the RK3576 (Rock 4D) versus the three core 6 TOPS NPU RK3588 (Rock 5B). Also I added in the RK3566 single core 1 TOPS NPU (Zero 3E) for comparison as other users were interested in that.
Overall the RK3576’s NPU is comparable, sometimes it performs a bit faster due to the Rock 4D having faster DDR5 memory. On inference models that have a lot of CPU post processing (such as Segmentation Models) these perform slower as the CPU cores are much slower. The raw CPU speed in the RK3576 is about the same as on the RPI 5.
2 Likes
This will always depend on particular task, what benchmarks are similar on those both?
4D is really interesting for me because of UFS (that can replace some nvme)
It would be nice to see 5b+ in this comparison 
I ran sbc-bench on the Rock 4D which you can compare to the Pi 5 results.
The other interesting thing about the RK3576 is it runs pretty cool. With the CPU stressed out it was sitting around 62 degrees C with only a small 10x15mm passive heat sink on it which makes it ideal for embedded products.
1 Like
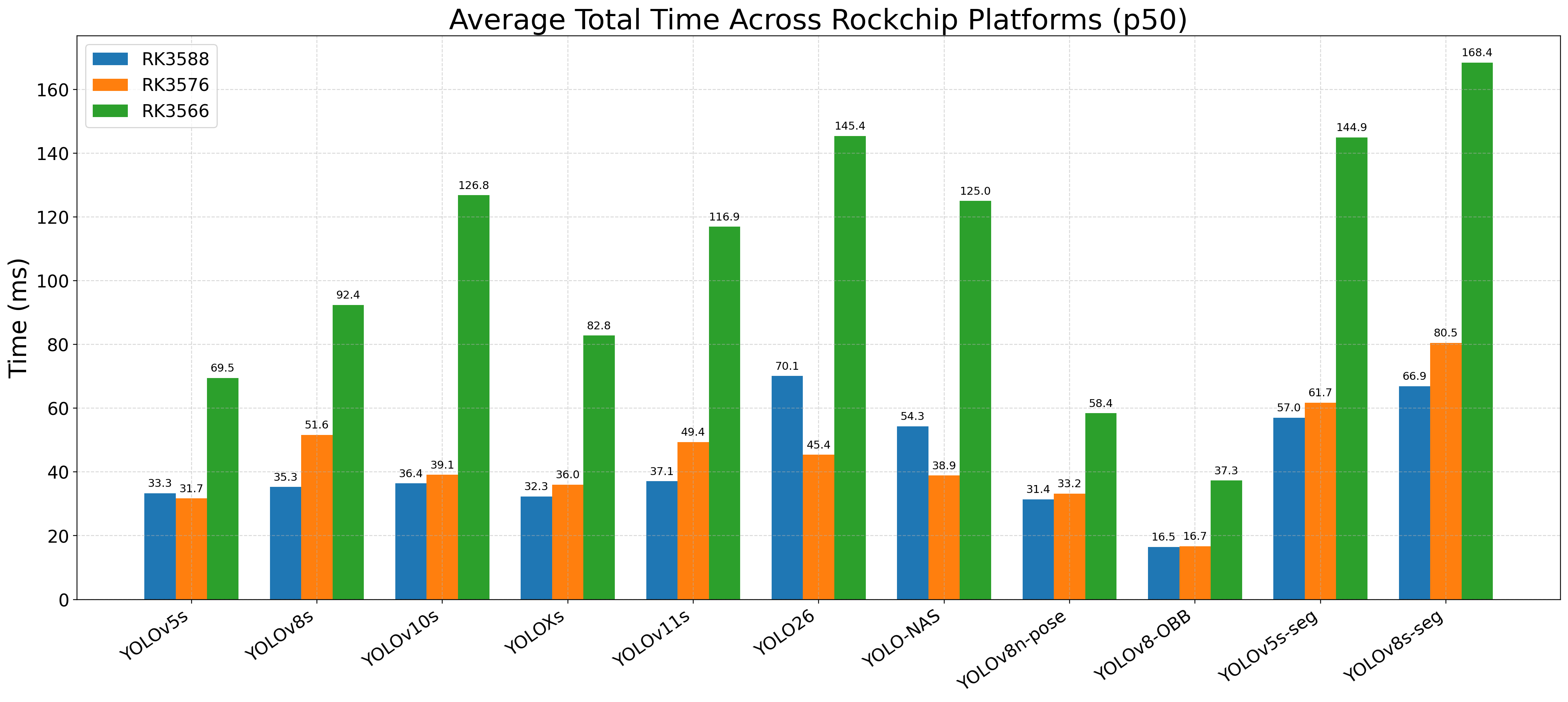
This week I refactored the YOLOv8-seg and YOLOv5-seg code and made a number of improvements over Rockchips C++ code which my Go code was based off.
The largest improvement was to use NEON/SIMD instructions for the Matmul calculations which gives a 6.7x speedup, dropping post processing from 47ms to 7ms. The C++ patch is available here.
I also implemented per object ROI mask resizing instead of Rockchips per object full frame resizes which gave another performance boost.
In addition to these segmentation model optimisations I also implement YOLO26 – but unfortunately we don’t see the performance improvement Ultralytics claims on the RK3588 NPU.
Overall we now have the new average (p50) per frame processing times.