
JFYI: you applied 8b10b coding twice 
ROCK 5B Debug Party Invitation
1 Like
Hi @DIYprojectz
Thanks for that information! I have also found a ZDNet article here that talks about the same topic: https://www.zdnet.com/article/are-sata-port-multipliers-safe/
This means I will try to use PCIe based cards only. However since I also want to use a regular M.2 drive as a system drive, I wonder whether you guys might know an adapter for this? Some posts above I was recommended to look for a M.2 to PCIe adapter and then another one that has multiple M.2 slots and uses a PCIe switch. Sadly the only adapter cards I can find seem to be rather passive e.g. you require a full x16 slot for four M.2 drives. I would not even bother to have the reduced bandwidth and use bifurcation and PCIe 3.0 1x everywhere but not even this seems to be available… 
1 Like
So what? This ‘article’ is based on this 2 pages PDF file (called a ‘paper’ – ROTFLMAO).
A student uses a Marvell Armada 300 board with 2 SATA ports and an unnamed ‘SATA PM’ in an experiment destroying multiple HDDs to draw laughable conclusions. Neither the said port multiplier is named nor whether it’s CBS or FIS-based switching nor any detail about the test setup (maybe they were stupid enough to create a mdraid?) nor any word about software support situation. The time spent on making graph(ic)s would’ve been better spent on providing a bunch of details what they were actually doing!
If this ‘academic paper’ is the only source of the ‘SATA PMs are unreliable’ urban myth then I honestly don’t give a sh*t 
That said I personally tested cheap/crappy SATA PMs like JMB321 and they led to data corruption for the simple reason that they were overheating. You get what you pay for… as usual.
Another overlooked issue (by consumers and ‘NAS enthusiasts’) is cable/connector quality (internal SATA connectors are rated for 50 matings max) and the simple statistical truth that a problematic cable between host and a 5-port SATA PM affects up to 5 and not just 1 disk. SMART attribute 199 is also unknown to most people (reported CRC errors as an indicator for cable/connector failures resulting in retransmissions and probable data corruption).
2 Likes
what i meant is that it’s stupid to have pciev2 with only one line.
I would have liked two lines.
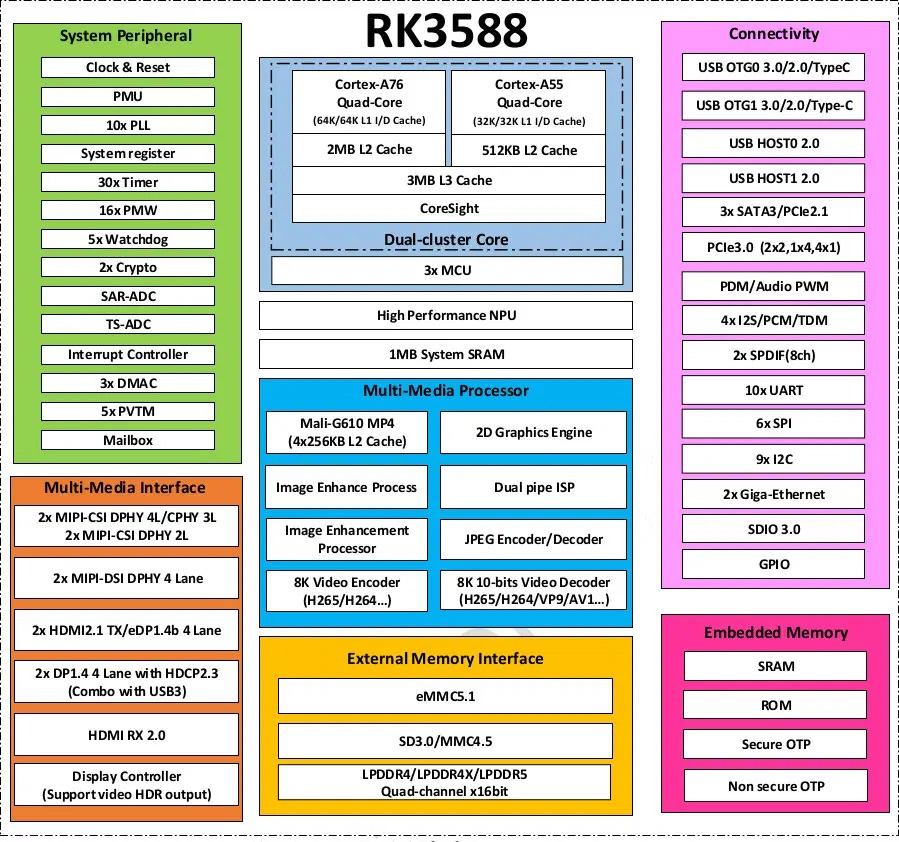
RK3588 consists of one PCIe 3.0 controller featuring four Gen3 lanes (M.2 key M slot) and there are three Combo PIPE PHY interfaces multiplexing the following protocols: PHY0/1: SATA / PCIe Gen2, PHY2: SATA / PCIe Gen2 / USB3.
Now check how the RTL8125BG network chip is connected, check count of USB3-A ports and you know why there’s just one PCIe lane (or native SATA) available at the key E slot.
2 Likes
yes you are right, but I am capricious.
I sometimes demand the impossible.
Ah yes. You are correct. Than it’s 4 Gbits/s
That’s for m.2 to x16.
https://aliexpress.ru/item/4000928573255.html
Based on rk3588 schematics I believe that one lane of pcie 2.1 was taken by RTL8225BG.
And Allen is talking about making 1 Gb/s port, but having 2 lanes on e-key pcie (not like i agree with it, since for mass-market it’s more important to have 2.5G and placement for wifi, rather than going for ~10Gbit on single port)
2 Likes
Radxa could’ve gone with GbE by using one of the two GMACs RK3588 provides. But fortunately they didn’t (see @willy’s insights above – RealTek really improved a lot over the last decades, even the 8111 PCIe NICs are fine starting with revision G).
I hate to quote Stuart but ‘it is as it is’ and they chose better network connectivity over another disposable Gen2 PCIe lane.
4 Likes
@Dante4 I have also seen a few adapters like those but since there are no visible chips on them (and they are very cheap) I would assume that they are just x16 slots where only the first four lanes are connected to something. Hence if I put an extension card there that expects/requires 16 actual lanes, it will not work as expected
Maybe I just try the port multiplier solution and hope for the best if the worst case is that the last written data might be corrupt, I don’t care…
Thanks for your help guys!
1 Like
No, that doesn’t work like this. As you may see in my post - I used PCIe switch, and that worked perfectly fine. Any (and by any I mean ANY) pcie device ALWAYS detect pcie version and amount of pcie lines available to it. So if you input x16 device in x4 lanes - device will go down to x4 lanes
2 Likes
@willy I found another funny PVTM example (part of sbc-bench results collection): http://ix.io/47IO
cpu cpu0: pvtm=1436
cpu cpu0: pvtm-volt-sel=2
cpu cpu4: pvtm=1649
cpu cpu4: pvtm-volt-sel=3
cpu cpu6: pvtm=1662
cpu cpu6: pvtm-volt-sel=3
For whatever reasons highest cpufreq OPP is 2352 (maybe configured manually by tweaking DT) but this results in some MCU declining high clockspeeds totally and limiting the upper end to below 400 MHz
Cpufreq OPP: 2352 Measured: 394 (394.973/394.794/394.738) (-83.2%)
Cpufreq OPP: 2208 Measured: 2099 (2099.382/2099.360/2099.164) (-4.9%)
Cpufreq OPP: 2016 Measured: 1975 (1975.674/1975.674/1975.239) (-2.0%)
Cpufreq OPP: 1800 Measured: 1803 (1803.289/1803.269/1803.208)
Cpufreq OPP: 1608 Measured: 1601 (1601.416/1601.377/1601.277)
Cpufreq OPP: 1416 Measured: 1436 (1436.630/1436.454/1436.326) (+1.4%)
Cpufreq OPP: 1200 Measured: 1183 (1184.341/1184.246/1183.392) (-1.4%)
Cpufreq OPP: 1008 Measured: 967 (967.415/967.324/967.166) (-4.1%)
Cpufreq OPP: 816 Measured: 778 (778.755/778.746/778.719) (-4.7%)
Cpufreq OPP: 600 Measured: 592 (592.871/592.725/592.632) (-1.3%)
Cpufreq OPP: 408 Measured: 394 (394.987/394.955/394.844) (-3.4%)
PVTM at work
That’s extremely strange. I’m more eager to thinking that there was a measurement error, e.g. opp being reported at some point and for whatever reason the idle calculation went wrong and the frequency instantly dropped to the lowest value during the measurement, or something like this. Or maybe this was run with the CPU overheating, causing it to instantly drop to the lowest bin during the test. But I do not see this being the result of a mistake in that non-fully-transparent chain, because the sel values only select an OPP entry and if your OPP is correct it should set the appropriate frequency. Or maybe the opp entry was slightly modified and the cpufreq code, not finding it, went to the lowest, but that sounds fishy.
I would believe we’re seeing cpufreq driver and one of those Cortex-M cores responsible for CPU doing different/counterproductive things?
Testing HDMI In. Preliminary tests.
Attached a 1920x1080 HDMI output to HDMI in:
[21875.917051] rockchip-hdptx-phy-hdmi fed60000.hdmiphy: hdptx phy pll locked!
[21875.917324] rockchip-hdptx-phy-hdmi fed60000.hdmiphy: hdptx phy lane locked!
[21875.917403] dwhdmi-rockchip fde80000.hdmi: don't use dsc mode
[21876.122474] dwhdmi-rockchip fde80000.hdmi: dw hdmi qp use tmds mode
[21876.133357] dwhdmi-rockchip fde80000.hdmi: use tmds mode
[21891.752972] rk_hdmirx fdee0000.hdmirx-controller: hdmirx_audio_interrupts_setup: 1
[21891.768465] fdee0000.hdmirx-controller: hdmirx_wait_lock_and_get_timing signal lock ok, i:2!
[21891.799180] fdee0000.hdmirx-controller: Vertical Sync threshold reached interrupt 0x2
[21891.864144] fdee0000.hdmirx-controller: hdmirx_format_change: New format: 1920x1080p59.99 (2200x1125)
[21892.306028] rk_hdmirx fdee0000.hdmirx-controller: hdmirx_delayed_work_audio: enable audio
[22265.859719] fdee0000.hdmirx-controller: stream start stopping
[22265.868370] fdee0000.hdmirx-controller: stream stopping finished
[22313.061071] fdee0000.hdmirx-controller: stream start stopping
[22313.069655] fdee0000.hdmirx-controller: stream stopping finished
[22330.790558] fdee0000.hdmirx-controller: stream start stopping
[22330.794873] fdee0000.hdmirx-controller: stream stopping finished
[22723.155749] fdee0000.hdmirx-controller: rcv frames
[22724.339221] fdee0000.hdmirx-controller: stream start stopping
[22724.347802] fdee0000.hdmirx-controller: stream stopping finished
v4l2-ctl -d /dev/video20 -V -D
Driver Info:
Driver name : rk_hdmirx
Card type : rk_hdmirx
Bus info : fdee0000.hdmirx-controller
Driver version : 5.10.66
Capabilities : 0x84201000
Video Capture Multiplanar
Streaming
Extended Pix Format
Device Capabilities
Device Caps : 0x04201000
Video Capture Multiplanar
Streaming
Extended Pix Format
Format Video Capture Multiplanar:
Width/Height : 1920/1080
Pixel Format : 'BGR3' (24-bit BGR 8-8-8)
Field : None
Number of planes : 1
Flags : premultiplied-alpha, 0x000000fe
Colorspace : BT.2020
Transfer Function : Unknown (0x000000b8)
YCbCr/HSV Encoding: Unknown (0x000000ff)
Quantization : Default
Plane 0 :
Bytes per Line : 5760
Size Image : 6220800
capture -d /dev/video20 -f BGR3 -s 1920x1080 -k 100 -v
Available pixel formats for /dev/video20:
BGR3 (33524742), 24-bit BGR 8-8-8, flags = 0
NV24 (3432564e), Y/CbCr 4:4:4, flags = 0
NV16 (3631564e), Y/CbCr 4:2:2, flags = 0
NV12 (3231564e), Y/CbCr 4:2:0, flags = 0
Control id: 10488164 - Power Present
Setting pixel_format: BGR3 (1920x1080)
Image size: 4147200 (1920x1080)
frame count: 1 - frames to skip: 100 - max. time: 0
fps: 56.80 - frame: 101 - size: 6220800 - elapsed: 1777892.
almost there:
conversion done with:
convert -size 1920x1080 -depth 8 test.bgr test.png
Also:
v4l2-ctl -d /dev/video20 -vwidth=1920,height=1080,pixelformat=BGR3 --stream-mmap --stream-skip=3
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< 60.00 fps
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< 60.00 fps
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< 60.00 fps
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< 60.00 fps
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< 60.00 fps
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< 60.00 fps
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< 60.00 fps
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< 60.00 fps
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< 60.00 fps
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< 60.00 fps
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<^C
The next step is to encode the stream to mp4.
What about a loop back? Grabbing frames from Rock 5B hdmi out to hdmi in? Yes, it works.
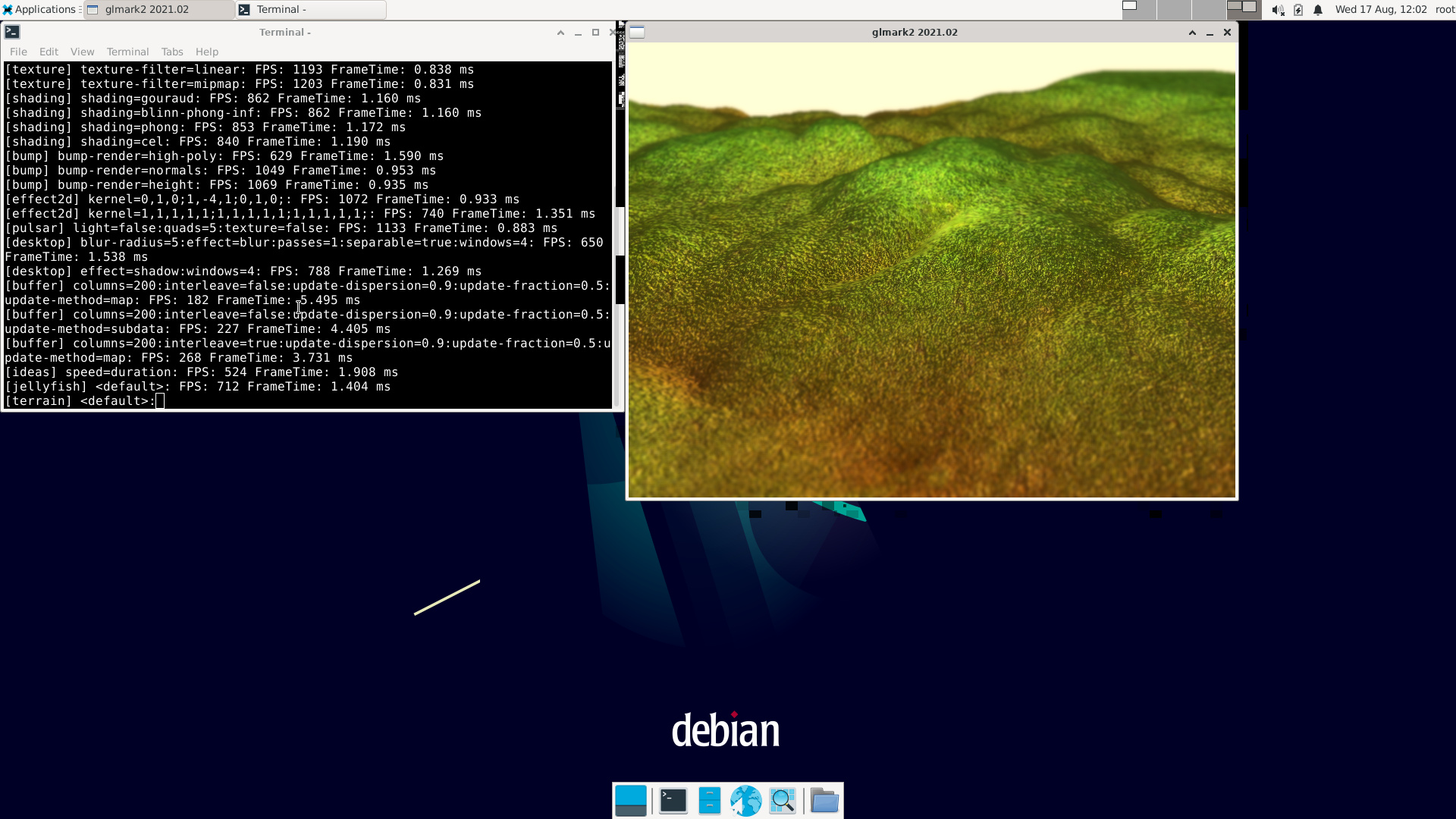
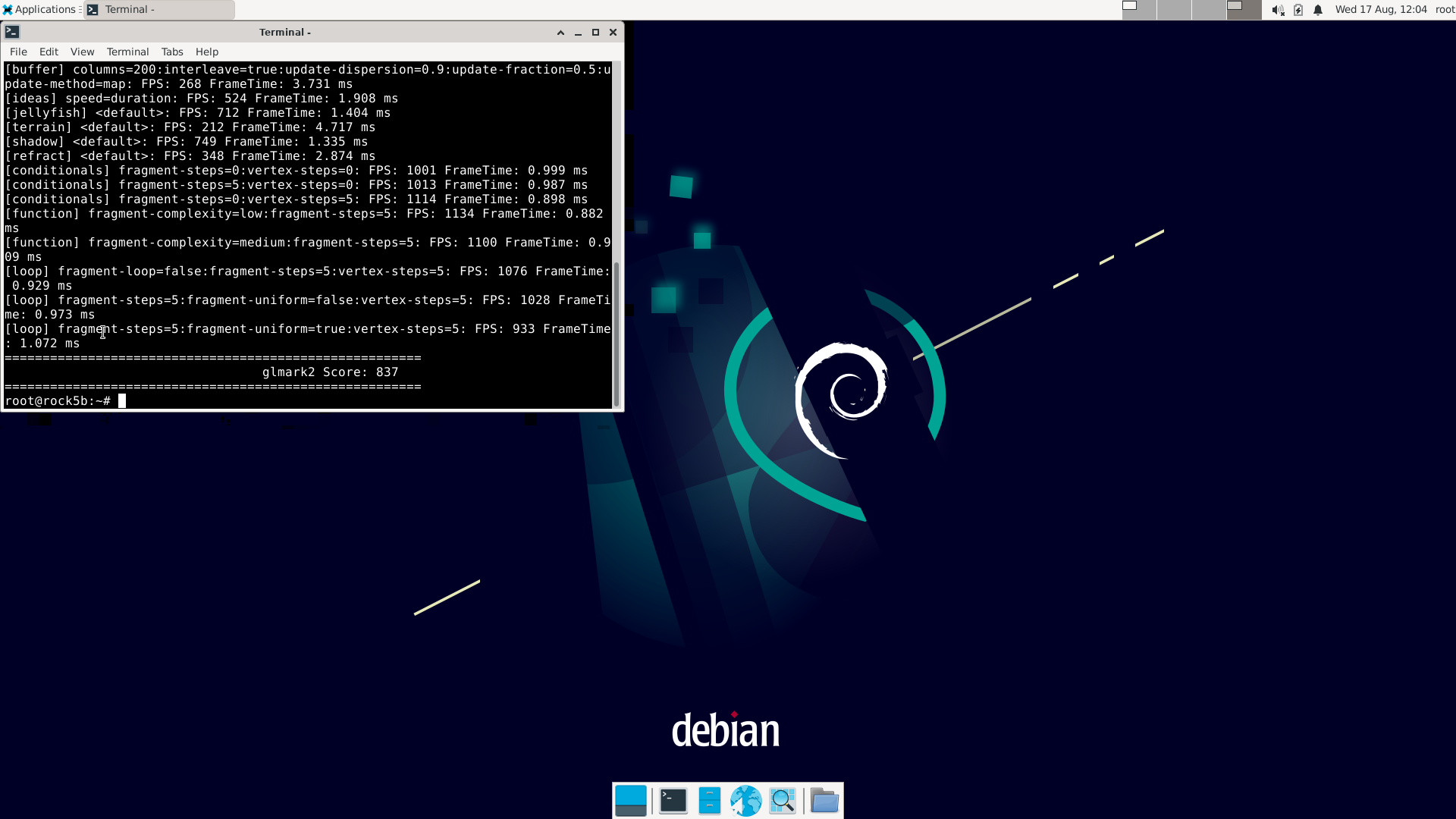
Hardware Encoding (H264) takes ~2% CPU usage (1.3% ~1.7%). Finally, a platform where you can make videos with HDMI input. Worked well with FHD at least. 4K not tested. Maybe I’ll find a 4K TV and try it out.
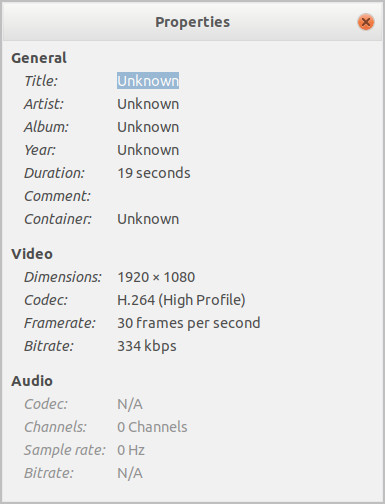
I am using the default mpp parameters, you can set “gop reference mode”, “bps” and “frame rate”, but that is for the video encoder experts, if you want me to try with some parameters, let me know.
Here is the encoded output (1920x1080, 60 Hz, 30 fps, 600 frames)
out_600frames_1920x1080.h264.zip (735.8 KB)
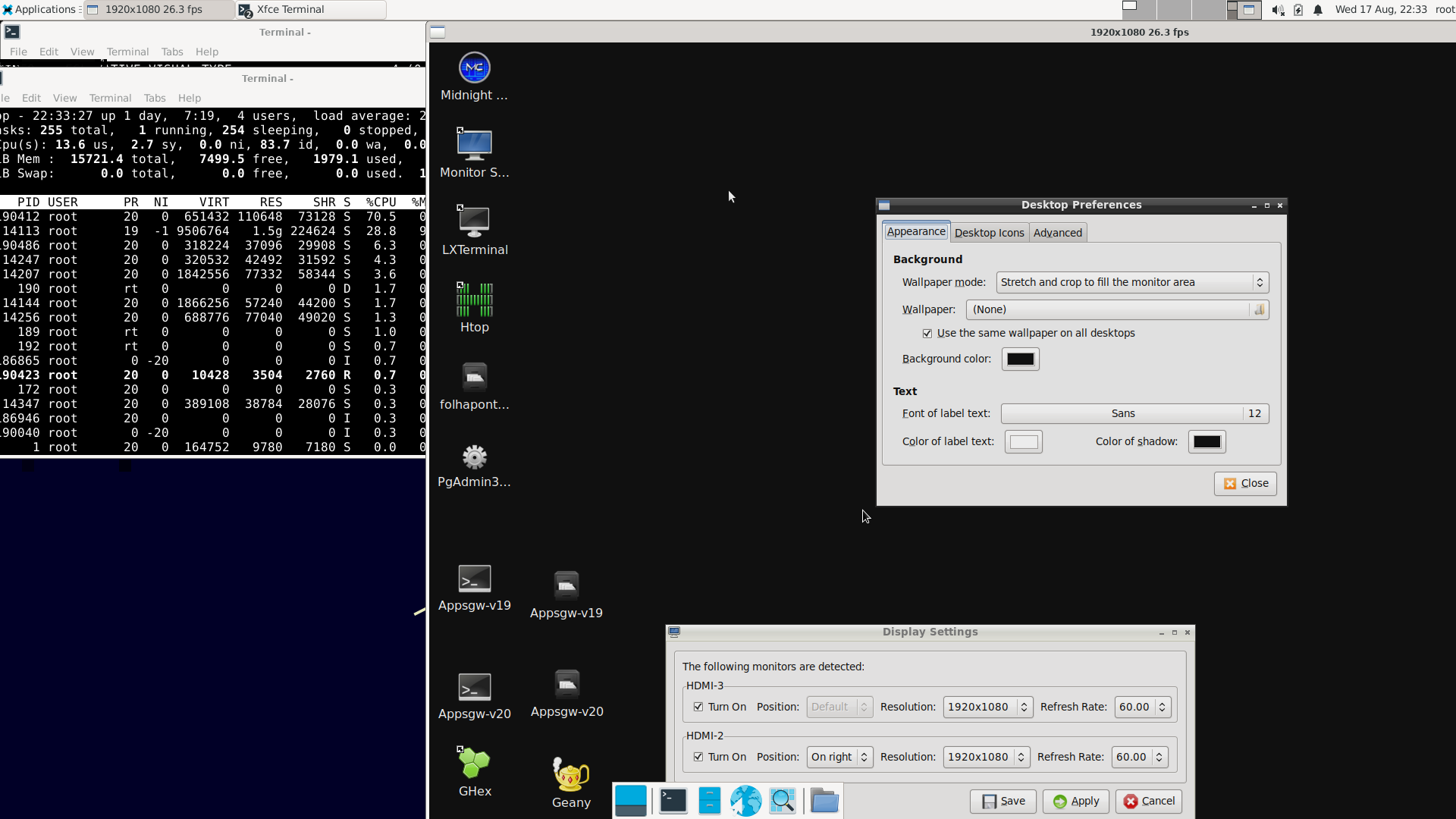
Rendering the BGR frames with SDL. Not really optimized, the best option would be to use NV12, i haven’t found a way yet, any suggestion?
2 Likes
@hipboi,@jack,
Please, consider providing an option for buying a camera FPC with a length of 20 cm, 25 cm, or maybe 30 cm for robotic projects. Can you share if the final product will have a different flex cable? I can see you are preparing for new camera sensors.
2 Likes
Presumably one could also use a cheaper board based around the ASM2812, like this:
3 Likes
Progress is being made on replacing the GPU firmware…
root@rock-5b:/sys/kernel/debug# echo 'Hello, World!' >mali0/fw_traces
root@rock-5b:/sys/kernel/debug# cat mali0/fw_traces
Hello, World!
So I can now send and receive messages from my firmware image through tracebuffers.
Unfortunately I’m having problems with getting exception returns to work, so I have to use polling rather than waiting for an interrupt.
Does anyone with experience with microcontrollers have any idea why an exception body that is nop; bx lr with 0-3 NOPs works fine, or 16-19, but not 4-15 NOP instructions?
i.e. the return instruction faults if it is not in the first eight bytes of a cacheline.
I’m defining the function like this:
__attribute__ ((naked, optimize("align-functions=64")))
static void
irq_handler_doorbell(void) {
asm volatile(
"nop \n"
"nop \n"
"bx lr \n");
}
The fault shows up in dmesg like this:
[ 4582.644400] mali fb000000.gpu: Unexpected Page fault in firmware address space at VA 0x0000000000FFFFE0
raw fault status: 0x7CD002C2
exception type 0xC2: UNKNOWN
access type 0x2: READ
source id 0x7CD0
2 Likes
After enabling the MPU and doing a bunch of other stuff, exception returns seem to have magically fixed themselves.
The MPU is working fine as well:
HardFault:
HFSR: vecttbl=0 forced=1 debugevt=0
CFSR: daccviol
MMFAR: 00004000
MSP / handler
pc : 01000166 lr : 01000195
sp : 0203fef0 ip : 0409a067 fp : 00000000
r7 : 0203fef0 r6 : 00000000 r5 : 04001710 r4 : 04001794
r3 : 00004000 r2 : 00000000 r1 : 0280001c r0 : 0203ff18
1 Like
I would like to report an issue. I think it’s been thoroughly discussed here, but since I haven’t stressed the board enough, I’ve never had this issue, until now.
My board has the exact same configuration (and batch number) as that of @CNXSoft.
I have been doing the builds natively (deb packages), using the eight cores. The builds are usually small, and i don’t cross-compile the apps i am testing. In fact, i have some linkage errors that a rockchip staff member could not reproduce, but maybe this is not related to the issue.
To make it short, since my kernel was somehow old, i cross-compiled the kernel with the latest patches and booted with the new kernel. Later, i decided to build the kernel natively. during the build, the board started to slow down, and the build crashed. (core dump). There was no overheating. I had to reboot the board. Unfortunately, eMMC got corrupt and the fs could not even be restored (no partition anymore).
I am using the radxa power supply.
I think these patches may have something to do with the issue (not really sure):
Can someone share what can be monitored in /sys so i can try to add it to htop and see the values in real-time? I will remove the patches and redo everything and see what i get.
Maybe the 64GB DRAM timings need to be addressed?
UPDATE:
Here is what is left from the 64GB eMMC that came with the board:
[ 147.852130] usb-storage 8-2.1:1.0: USB Mass Storage device detected
[ 147.852245] scsi host7: usb-storage 8-2.1:1.0
[ 148.882101] scsi 7:0:0:0: Direct-Access Generic Mass-Storage 1.11 PQ: 0 ANSI: 2
[ 148.882370] sd 7:0:0:0: Attached scsi generic sg5 type 0
[ 149.624090] sd 7:0:0:0: [sde] 11376640 512-byte logical blocks: (5.82 GB/5.42 GiB)
[ 149.629086] sd 7:0:0:0: [sde] Write Protect is off
[ 149.629088] sd 7:0:0:0: [sde] Mode Sense: 03 00 00 00
[ 149.634086] sd 7:0:0:0: [sde] No Caching mode page found
[ 149.634090] sd 7:0:0:0: [sde] Assuming drive cache: write through
[ 149.722086] sd 7:0:0:0: [sde] Attached SCSI removable disk
Damaged or worn down?
Luckily i have a spare 64GB eMMC saved here for Rock 3A. i will redo everything and cross my fingers.